최신보고서



- TAG
- #증권업 경쟁력 강화 시리즈
목차
Ⅰ. 서론
Ⅱ. 생성형 AI(Generative AI)와 언어모형의 이해
1. 파운데이션 모형(Foundation Model)과 생성형 AI의 발전
2. 대형언어모형의 구조
3. 금융투자업에서의 언어모형 활용 방안
Ⅲ. 금융정보분석에서의 대형언어모형 활용 방안
1. 실무에서의 활용을 위한 맞춤화(customization) 방식
2. 정성적 분석: 공시 정보의 요약 및 추출
3. 정량적 분석: 재무 지표의 분석
Ⅳ. 대형언어모형 활용의 위험 및 제약 요인
1. 할루시네이션 효과와 대응 방안
2. 대형언어모형 활용의 제약 요인
Ⅴ. 결론 및 시사점
Ⅱ. 생성형 AI(Generative AI)와 언어모형의 이해
1. 파운데이션 모형(Foundation Model)과 생성형 AI의 발전
2. 대형언어모형의 구조
3. 금융투자업에서의 언어모형 활용 방안
Ⅲ. 금융정보분석에서의 대형언어모형 활용 방안
1. 실무에서의 활용을 위한 맞춤화(customization) 방식
2. 정성적 분석: 공시 정보의 요약 및 추출
3. 정량적 분석: 재무 지표의 분석
Ⅳ. 대형언어모형 활용의 위험 및 제약 요인
1. 할루시네이션 효과와 대응 방안
2. 대형언어모형 활용의 제약 요인
Ⅴ. 결론 및 시사점
- 요약
- 생성형 AI(Generative AI)와 대형언어모형(Large Language Model)의 관심도 증가는 최근 이를 활용한 생산성 혁신에 대한 가능성에 대한 논의로 발전하고 있다. 특히 범용성과 인지적 능력을 보조할 수 있는 기술적 특징으로 인하여 여러 산업 분야에 걸쳐 고부가가치 업무를 보조하는 기술로서 생성형 AI를 활용하는 방안이 연구되고 있다. 이에 본 연구에서는 금융정보의 분석 업무에서 생성형 AI의 일종인 대형언어모형을 활용할 수 있는 방안을 제시하여 금융투자업에서의 활용 가능성을 진단하였다. GPT를 사용하여 KOSPI 200 기업의 영업 및 재무 현황을 분석한 결과, 적절한 맞춤화 과정을 통해 복잡하고 긴 공시자료를 효율적으로 요약하여 정보를 추출할 수 있음을 확인하였다. 그러나 GPT가 추출 및 요약한 정보의 사실성에 대한 검증이 필요하며 공시일 전후의 시장 변동성과 통계적으로 유의미한 관계를 찾기 어렵다는 점에서 향후 추가적인 개선 방안에 대한 연구가 필요하다.
낙관적인 기대감에 기반한 대형언어모형의 급격한 확산은 동시에 실무적인 차원에서 위험 요소와 제약 요인에 대한 고민을 유발하고 있다. 대표적인 위험 요소로서 대형언어모형이 답변을 작성하는 과정에서 근거가 부족하거나 거짓을 사실인 양 출력하는 문제가 있으며 제약 요소로서 초거대 모형을 학습 및 유지할 수 있는 인적, 물적 자원의 부족을 들 수 있다. 이와 같은 요소들에 대하여 발생 원인을 분석하고 그에 따른 대응 방향을 본 연구를 통해 논의하였다. 대형언어모형의 성공적인 도입을 위하여 기술적인 측면에서 고품질 학습 데이터의 수집과 처리를 위한 인프라의 구축과 더불어 구조적인 측면에서 IT 역량의 강화를 위한 투자를 확대할 필요가 있을 것이다.
Ⅰ. 서론
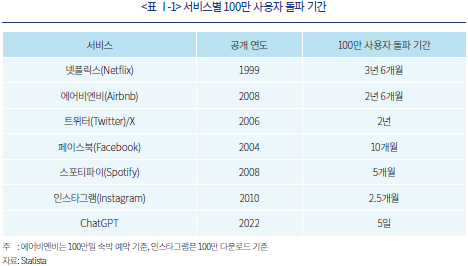
수많은 웹 기반 서비스 중에서도 생성형 AI(Generative AI)만큼 급격하게 대중의 관심을 얻은 사례는 찾기 어려울 것이다. OpenAI가 제공하는 생성형 AI 기반 언어모형의 대표주자인 ChatGPT는 최단기간 안에 100만 사용자를 돌파한 바 있다(<표 Ⅰ-1> 참조, 2023년 6월 기준). 이와 같은 폭발적인 인기의 이면에는 생성형 AI의 활용 가능성에 대한 기대와 오해가 공존하고 있다. 이에 본 고에서는 생성형 AI의 일종으로서 폭넓은 적용 가능성을 보인 대형언어모형(Large Language Model: LLM)의 기반 기술을 설명하고 예시를 바탕으로 금융정보분석에의 활용 방안을 모색하고자 한다.
ChatGPT의 대중적인 관심은 흥미의 단계를 넘어서 생성형 AI를 활용한 생산성 혁신의 가능성을 논의하는 단계로 접어들고 있다. 글로벌 컨설팅 기업 McKinsey & Company의 연구보고서는 생성형 AI의 확산이 여러 산업 분야에 걸쳐 약 2.6조달러에서 4.4조달러의 가치를 새롭게 창출할 것으로 예상하였다(McKinsey Global Institute, 2023). 생성형 AI가 이처럼 큰 파급 효과를 불러올 수 있었던 이유로는 크게 두 가지를 지적할 수 있다. 첫 번째는 기술의 범용성으로서, 거대한 규모에서 나오는 의외성(혹은 창의성)을 바탕으로 모형을 다양한 산업군과 업무 분야에 맞춤화(customize)할 수 있다. 이는 향후 미국 내 약 80% 정도의 직업군에서 생성형 AI를 사용하게 될 것이라는 Eloundou et al.(2023)의 예측과도 일치하는 것이다. 두 번째 이유는 생성형 AI가 기존의 혁신 기술과 달리 인지적(cognitive) 능력을 보조하는 도구로 개발되었다는 점이다. Baily et al.(2023)의 연구에서 확인되었듯이, 생성형 AI는 주로 고소득 직업에서 요구되는 프로그래밍, 작문, 연구 등의 고부가가치 업무를 보조할 수 있다.
생성형 AI 및 대형언어모형을 경제ㆍ금융정보 분석에 적용하는 연구 또한 진행되고 있다. 서범석ㆍ이영환ㆍ조형배(2022)는 뉴스 기사의 경기에 대한 심리적 기대감을 지수화하는 모형을 개발하였으며, Kim et al.(2023)은 사업보고서에서 유용한 정보를 추출하는데 GPT를 활용하는 방안에 대한 실증분석을 진행하였다. 최근에는 금융 분석 전반에 사용될 수 있는 범용 언어모형을 개발하려는 노력 또한 진행되고 있다(Yang et al., 2023; Wu et al., 2023).
생성형 AI의 효용에 대한 낙관적인 기대는 금융산업 여러 분야에서 실험적인 도입으로 이어지고 있으나(이효섭, 2023), 실무적인 차원에서의 확산을 어렵게 하는 요소 또한 존재하고 있다. 모형 내적인 요소로는 기존에 없는 정보를 생성하는 과정에서 근거가 부족하거나 거짓인 내용을 마치 사실처럼 서술하는 할루시네이션(hallucination) 문제를 지적할 수 있다. 이와 더불어 초거대 AI 모형을 개발하고 적용하는 데 필요한 비용이 급격하게 증가하고 있어 부담으로 작용할 수 있다.
이와 같은 문제의식을 바탕으로 본 고에서는 대형언어모형의 운용 원리를 분석하고, 실무적 활용 방안과 더불어 그 과정에서 발생 가능한 문제점들에 대한 대응 방향을 제시하고자 한다. 제Ⅱ장에서는 생성형 AI의 기반 구조와 발전 과정을 소개하고 대형언어모형의 작동 원리를 설명하였다. 제Ⅲ장에서는 대형언어모형을 활용하여 금융정보를 분석하는 방안과 그 효용성을 실증적으로 평가하였다. 제Ⅳ장에서는 앞서 설명된 활용 방안과 관련하여 예상되는 리스크 요인을 분석하고 대응책을 제시하였다. 마지막으로 제Ⅴ장에서는 국내 금융투자업 환경에서 대형언어모형의 개발 및 적용에 있어서 시사점과 개선 방향을 논의하였다.
Ⅱ. 생성형 AI(Generative AI)와 언어모형의 이해
생성형 AI는 포괄적인 의미에서 사용자가 입력한 프롬프트(prompt)에 따라 문자, 음성, 그림, 동영상 등 다양한 형태의 컨텐츠를 작성하는 AI 모형으로 정의할 수 있다. 생성형 AI의 기반이 되는 기술은 Vaswani et al.(2017)의 논문에서 처음 제안된 트랜스포머(transformer)로 볼 수 있다. 해당 논문은 트랜스포머 구조에 기반한 언어모형이 대규모의 데이터를 순차적으로 학습하여 영어-독일어 번역 문제에서 두 언어에 능통한 인간과 유사한 결과를 만들어 낼 수 있음을 보여준 바 있다. 생성형 AI의 기술적 특징으로서 이처럼 확률적인 답을 순차적으로 ‘생성(generate)’하는 구조는 마치 인간이 새로운 문장을 ‘창작(create)’하는 것과 유사하게 보인다는 점에서 큰 주목을 받고 있다.
1. 파운데이션 모형(Foundation Model)과 생성형 AI의 발전
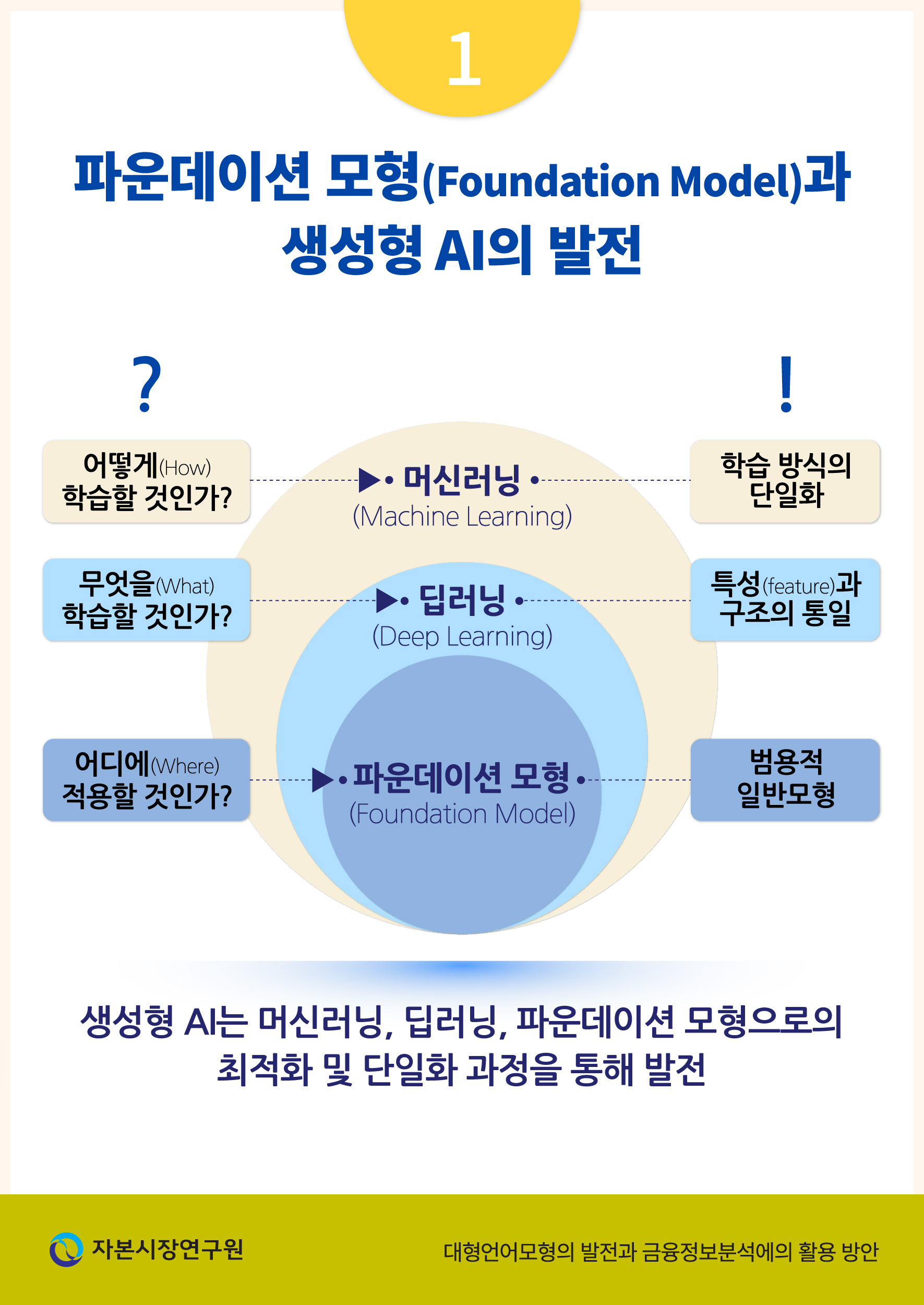
생성형 AI의 개발 배경을 이해하기 위해서는 현재 널리 활용되고 있는 파운데이션 모형(foundation model)이 최근 AI의 발전 과정에서 차지하는 위상을 논의할 필요가 있다. Bommasani et al.(2022)은 광범위한 데이터를 바탕으로 학습된 초거대 AI가 다양한 목적에 대하여 기반이 되는 모형으로 쓰일 수 있다는 점에 착안하여 이를 파운데이션 모형이라고 지칭하였다. 나아가, 생성형 AI가 탄생하기까지의 과정을 세분화하여 크게 세 가지의 기술 발전 단계–머신러닝(machine learning), 딥러닝(deep learning), 그리고 파운데이션 모형(foundation model)–으로 나누어 설명하였다. <그림 Ⅱ-1>에서는 각 단계의 기술이 AI의 발전 과정에서 상징하는 바를 기술적 과제의 대두와 그에 대한 대응을 중심으로 나타내었다.
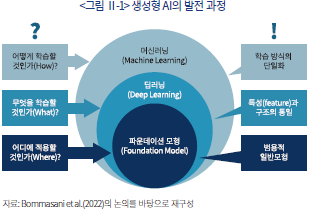
우선 머신러닝의 발전은 모형을 어떻게 학습시킬 것인지에 대한 방법론적인 과제의 대두에서 비롯되었으며 이는 학습 모형의 통합이라는 결과를 가져오게 된다. 이는 머신러닝 방법론이 성숙기에 접어든 시점에서 데이터를 학습하는 방식을 일원화하였다는 점에서 그 의미를 찾을 수 있다. 두 번째 발전 단계에서 딥러닝의 등장은 학습에 필요한 특성(feature)의 선정에 대한 고민에서 비롯하였으며 이를 통하여 모형의 구조(architecture)에 대한 일관된 접근을 가능하게 하였다. 마지막으로 파운데이션 모형의 등장은 앞서 머신러닝, 딥러닝 방법을 바탕으로 구축된 모형의 기능성(functionality)에 대한 고민에서 출발하였다고 볼 수 있다. 이에 대한 해답으로서 초거대 규모의 신경망에 기반한 파운데이션 모형은 범용성을 바탕으로 실무적인 차원에서 어떤 모형을 사용할지에 대한 (현재까지) 최선의 방안을 제시하였다고 평가할 수 있다.
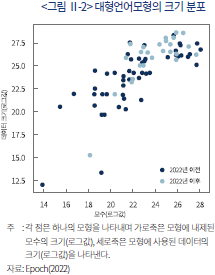
파운데이션 모형이 이와 같은 범용성을 나타낼 수 있게 된 주원인은 학습 데이터의 양적인 성장과 이를 학습시킬 수 있을 정도로 모형이 대형화된 것에서 찾을 수 있다. 최근 개발된 AI 모형들의 크기는 최근 더욱 급격하게 증가하고 있으며 동시에 모형이 학습할 수 있는 데이터의 규모 또한 과거에 개발된 AI 모형에 비해 매우 방대해지고 있다.1) 이와 같은 거대화 추세에 대하여 Sevilla et al.(2022)은 AI의 대형화 과정을 세 단계로 나누어서 설명하였다. 첫 번째 발전 단계는 딥러닝이 널리 사용되기 이전 단계로서 대략적으로 2010년 이전에 개발된 AI 모형들을 포함한다. 2010년 이후 딥러닝이 보편화되는 과정에서 모형의 크기는 폭발적으로 증가하고 있음을 해당 연구를 통해 분석하였다. 다음 발전 단계는 2015년 알파고(AlphaGo)의 개발을 기점으로 대형화 기조가 더욱 강화된 점을 지적하고 있다. 이와 같은 추세는 지속적으로 이어져 <그림 Ⅱ-2>에서 확인할 수 있듯이 초거대 언어모형들이 최근 더욱 집중적으로 개발되고 있다.
이처럼 방대한 자료를 학습한 파운데이션 모형은 그 거대함과 복잡함을 바탕으로 예상을 벗어나 주어진 문맥을 실시간으로 학습하는 양상을 보인다. 흔히 In-Context Learning(ICL)기능2)을 통하여 파운데이션 모형은 학습된 자료를 벗어나 마치 새로운 정보를 ‘생성(generate)’하는 것 같은 기능을 선보이게 된다. 예를 들어 GPT는 문학 작품을 만들고, 사용자의 지시에 따라 기존에 없던 그림을 그리며, 작곡을 하기도 한다. 이처럼 마치 창작에 가까운 과정을 통해 기존에 없던 자료를 만들어 내는 단계에 이른 AI 모형들로 인하여 생성형 AI의 개념이 대두하게 되었다.
2. 대형언어모형의 구조
모든 AI 기반 모형이 그렇듯 생성형 AI 또한 머신러닝 알고리즘을 바탕으로 방대한 양의 자료에서 다양한 연관관계 및 패턴을 학습하여 매개변수(parameter)를 계산한다. 여기서 흔히 사용되는 모형은 다층적인 신경망(neural network), 또는 딥러닝 모형이 사용되며 이는 기존의 딥러닝 기반 AI와 동일한 점이다. 그러나 전통적인 AI의 학습 과정이 일회성이고 정태적인 반면 생성형 AI는 지난 학습 과정에서의 출력물이 다음 학습 단계에서의 입력 정보가 되는 동태적, 중첩적인 과정을 거쳐 최종 결과물이 생성된다는 차이가 있다.3)
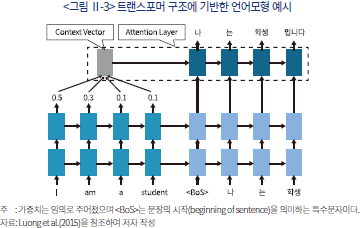
트랜스포머 구조의 중첩적인 처리 과정은 번역에 특화된 언어모형의 예시를 통해 쉽게 이해할 수 있다. <그림 Ⅱ-3>은 영어 문장을 한국어로 번역하는 트랜스포머 모형을 간략하게 표현한 것이다. 전처리 과정에서 텐서로 표현된 각 영어 단어는 미리 학습된 가중치를 곱하여 컨텍스트 벡터(context vector)를 형성하게 된다. 이와 더불어 텐서로 표현된 한국어 어휘 사이의 관계망을 다차원 행렬로 표현한 것이 어텐션(attention) 구조이다. 이와 같은 계산 과정을 통해 만들어진 출력문은 입력된 문장 전체를 참조할 뿐만 아니라 직전에 출력된 단어 또한 참조해서 최종 결과물을 산출하게 된다.
번역의 예시에서도 알 수 있듯이, 기존의 AI 모형들과 대비되는 생성형 AI의 특징으로 비전문가가 대부분을 차지하는 사용자(end user)가 직접 생성된 정보를 소비한다는 점을 들 수 있다. 따라서 다른 AI 응용 사례와 비교하였을 때 입력자료의 인코딩(encoding)과 더불어 출력 자료의 디코딩(decoding)이 중요해지고 있다.
3. 금융투자업에서의 언어모형 활용 방안
생성형 AI의 도입에 있어서 금융산업은 다른 산업군에 비하여 투자 규모면에서 상위권에 위치하고 있다(노성호, 2023). 특히, 최근 금융산업에서의 생성형 AI 활용 사례들은 챗봇을 활용한 고객 지원, 로보어드바이저(robo advisor)를 활용한 자산관리 효율화, 이상 거래 탐지 등 컴플라이언스 강화 등 다양한 업무 분야에 걸쳐서 나타나고 있다(이효섭, 2023). 이와 같은 사례에서 나아가 금융산업의 세부 분야로서 금융투자업에서 언어모형을 활용할 수 있는 방안을 앞 절에서 소개한 모형의 특성이 비추어 구체화하고자 한다.
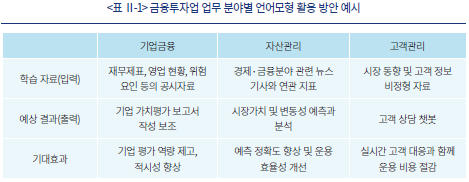
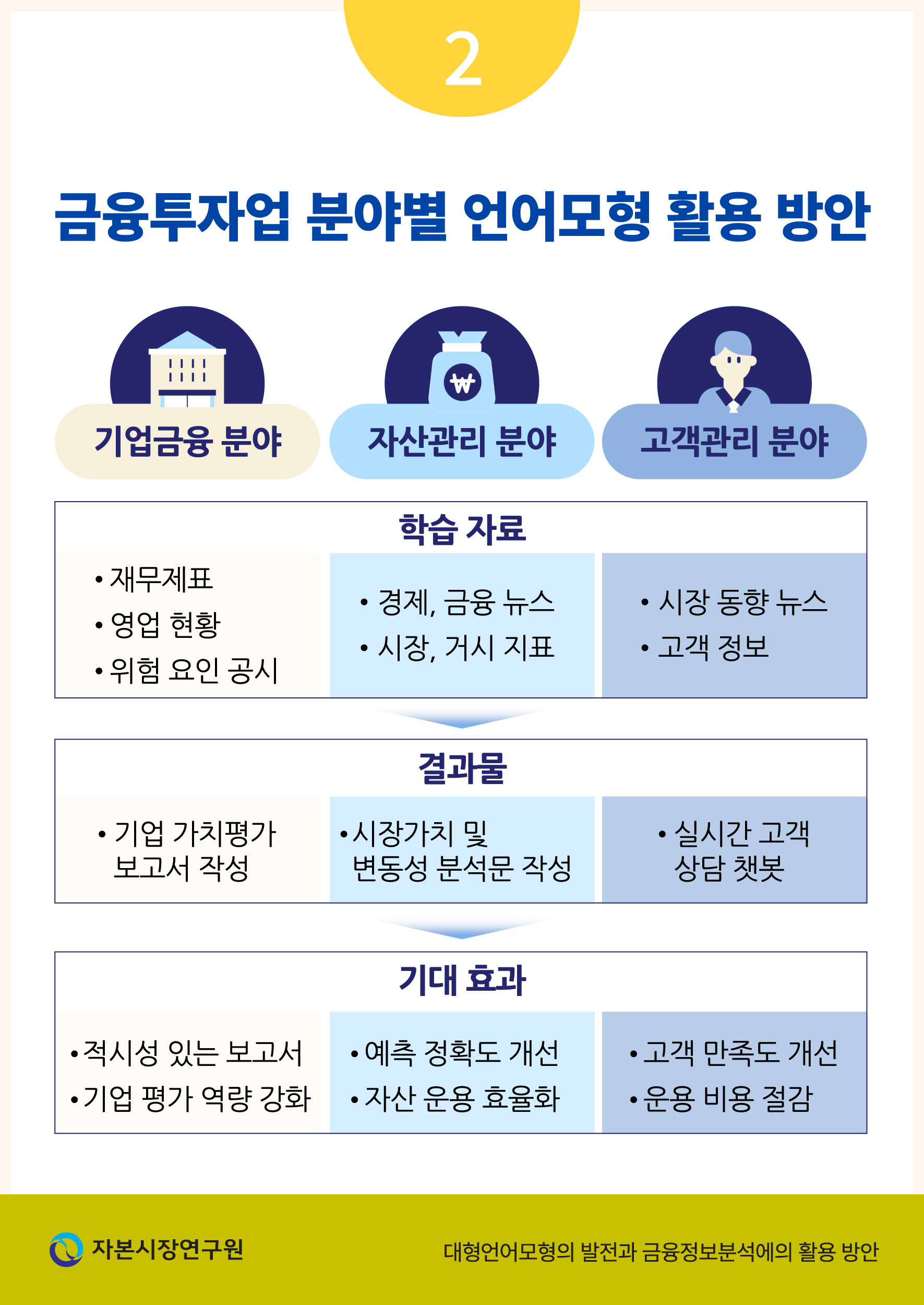
<표 Ⅱ-1>에서는 금융투자업의 여러 업무 분야 중 기업금융, 자산관리, 고객관리 측면에서 언어모형을 활용할 수 있는 방안에 대한 예시를 간략하게 제시하였다. 우선, 영업 현황에 대한 정보를 포함하고 있는 문자 정보를 학습한 언어모형을 기업 평가에 활용하는 방안을 고려할 수 있다. 학습된 자료의 정보적 연관성이 충분하다는 전제하에 이와 같은 모형을 통해 작성된 보고서는 다면적인 정보를 요약하여 기업 가치 평가 업무를 보조할 수 있다. 한편, 방대한 양의 경제 동향 관련 뉴스를 종합적으로 학습하고 필요한 정보를 요약하는 업무 또한 언어모형의 보조를 통해 효율성을 제고할 수 있다. 마지막으로 이미 금융업 여러 분야에서 활용하고 있는 고객 상담용 챗봇 또한 대형언어모형을 활용하여 정해진 답변에서 나아가 고객 정보와 시장 동향에 부합하는 답을 생성하는 방향으로 개선할 수 있을 것이다.
Ⅲ. 금융정보분석에서의 대형언어모형 활용 방안
1. 실무에서의 활용을 위한 맞춤화(customization) 방식
앞 절에서 설명한 바와 같이 파운데이션 모형에 기초한 대형언어모형의 가장 큰 장점은 대량의 정보를 미리 학습하여 추가적인 개량이 없이도 비교적 넓은 범위의 작업에 즉시 사용이 가능하다는 점이다. 그러나 실무적인 차원에서는 범용성을 가진 일반 모형보다는 목적에 부합하는 데이터를 추가로 학습시켜 맞춤화(customize)한 모형이 더 큰 활용성을 보일 수 있다.
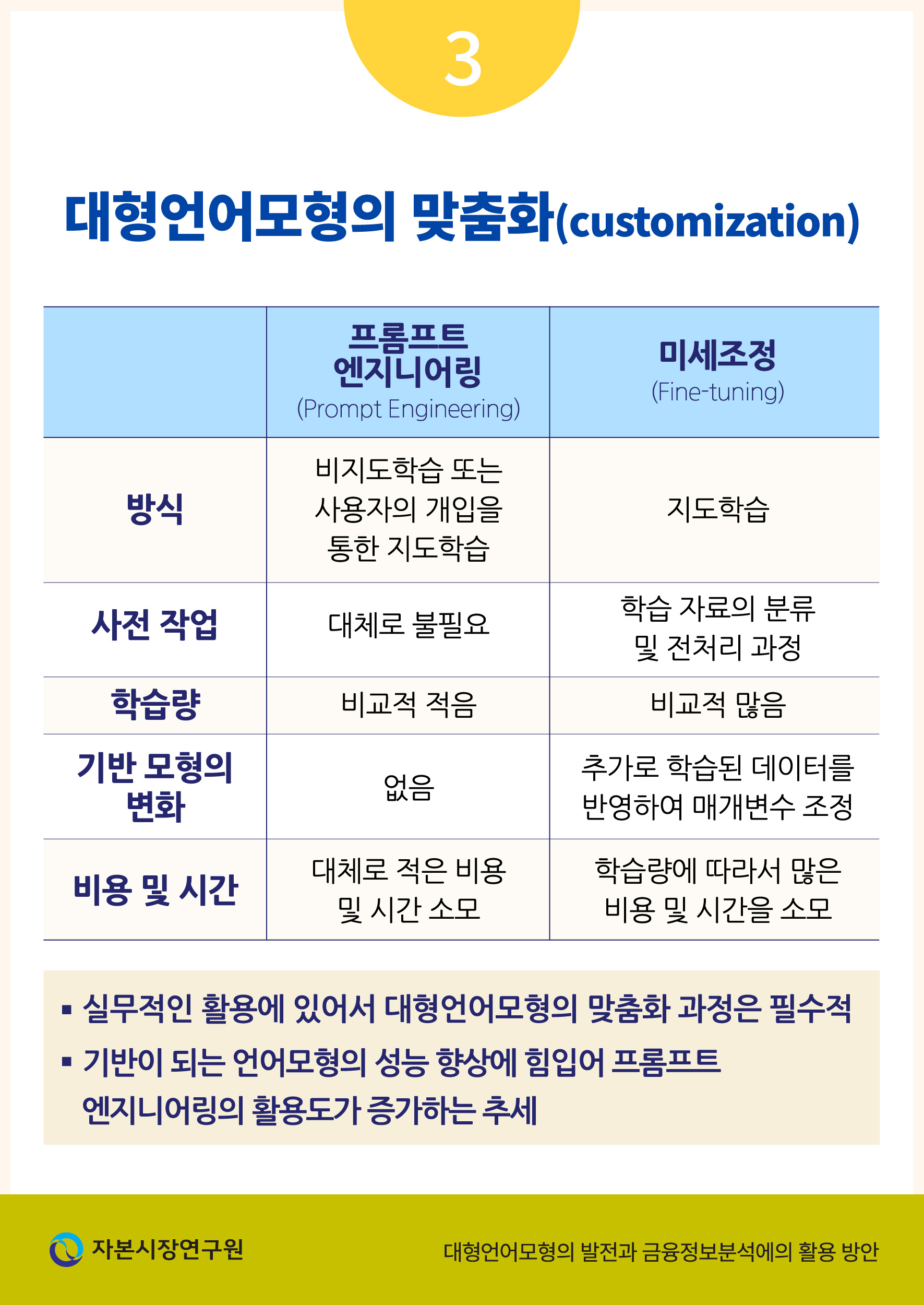
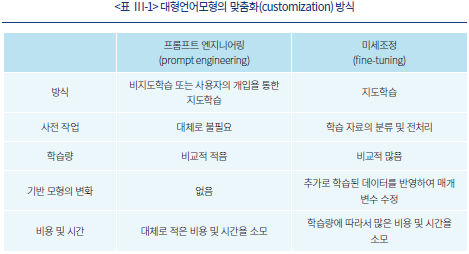
대형언어모형의 맞춤화 과정은 일반적으로 두 가지 방식을 통하여 이루어진다(<표 Ⅲ-1> 참조). 첫 번째로 프롬프트 엔지니어링(prompt engineering)은 사용자와의 (비교적) 짧은 문답을 통해 모형으로 하여금 추가적인 정보 또는 문맥에 맞는 답변 방식을 학습하고 이에 따라 개선된 결과를 제시하도록 유도하는 과정을 의미한다. 이와 같은 접근방식은 사용자가 달성하고자 하는 목적이 명확할수록 이를 모형이 비교적 빠르게 학습하는 장점이 있다.
두 번째로 미세조정(fine-tuning)은 앞서 설명한 프롬프트 엔지니어링과는 다르게 대량의 정보를 일괄적으로 학습시켜 모형의 구조, 특히 신경망 사이의 가중치를 변경하는 방식을 의미한다. 이 과정에서 모형은 지도학습(supervised learning) 방식으로 매개변수 및 가중치를 재조정하게 되며, 따라서 원하는 작업 또는 주제와 관련되었을 뿐만 아니라 레이블이 지정된 데이터가 필수적으로 사용된다. 더불어 거대한 모형을 다시 계산하는 과정이 필요한 만큼 개발 및 테스트에 많은 시간과 노력이 필요할 수 있다.
근래에 들어 GPT와 같은 대형언어모형을 실무에서 활용하기 위한 사전 조율 단계에서 미세조정보다는 프롬프트 엔지니어링을 통해 사용자가 개입하는 접근방식이 그 효율성을 인정받아 널리 활용되고 있다. 이 중 특히 언어모형에 적용되는 방식인 ICL은 비용 및 시간이 많이 들어가는 미세조정 방식 대비 효율이 높을 뿐만 아니라 대량의 말뭉치(corpus) 데이터에서 흔히 발견될 수 있는 문제인 허위 관계(spurious correlation)를 학습할 가능성을 낮춘다는 장점이 있다.
2. 정성적 분석: 공시 정보의 요약 및 추출
이 장에서는 앞서 설명한 대형언어모형의 구조와 활용 방식에 대한 이해를 바탕으로 금융정보의 분석에 활용할 수 있는 방안을 제시하고 그 효과를 분석하고자 한다. 예시에 사용된 모형은 흔히 ChatGPT로 알려진 GPT-3.5-turbo를 바탕으로 프롬프트 엔지니어링을 통해 보다 유용한 정보를 생성할 수 있도록 개선한 형태이다. 학습 자료는 KOSPI 200 기업의 반기보고서와 이에 상응하는 재무 지표를 활용 목적에 따라 선택적으로 사용하였다.
길고 복잡한 사업보고서와 재무제표를 요약하고 이해하는 과정은 기업의 가치를 평가하는 데 있어서 중요한 기초작업이지만 일반적으로 상당한 시간과 노력이 투입될 수 있다. 따라서 간단한 명령문을 활용하여 정보를 효율적으로 요약하는 방법을 살펴보고자 한다. <그림 Ⅲ-1>은 국내 대형 보험사의 2023년 1분기 영업 현황을 GPT로 요약하는 예시이다. 첫 번째 작업은 앞 절에서 설명한 ICL에 해당하는 단계로서 분석의 기반이 되는 자료를 모형에 사전적으로 학습(입력)시키는 것이다. 이는 아래 예시에서 system 역할에 반기보고서 중 영업의 현황 항목을 입력한 것을 의미한다. GPT는 사전에 학습된 트랜스포머 구조에 기반하므로 최신의 정보를 반영하고 있지 않으며, 따라서 이와 같은 학습 과정이 선행되지 않으면 사실에 근거한 답변을 기대할 수 없다.4) 이를 보완하기 위하여 사용자가 직접 목적에 부합하는 자료를 GPT에 제공하는 과정이 선행되었을 때 적어도 기초적인 사실관계에서 크게 벗어나지 않는 답변을 기대할 수 있다.
분석의 두 번째 요소는 사용자가 입력하는 명령이다. OpenAI에서 제안한 GPT의 올바른 활용 방안에 따르면 명령문이 구체적이고, 예시와 함께 작성되었을 때 보다 효과적인 답변을 기대할 수 있다.5) 아래의 예시에서는 명령문을 작성하는 과정에서 영업의 현황을 국내, 해외, 그리고 기타 사업 분야로 나누어 설명할 것을 주문하였다. 따라서 답변 또한 system 프롬프트에서 제공된 대량의 정보에서 명령문에 포함된 세 분야에 높은 비중을 부여하여 요약 과정에서 발생할 수 있는 정보의 무작위적 손실을 줄일 수 있다.
마지막 단계이자 GPT 활용의 가장 중요한 과정으로서 출력된 답변에 대한 검증 또한 필요하다. 사전 학습과 구체적이고 유의미한 명령문 작성의 단계를 통하여 답변의 정확도를 높일 수 있으나, 언어모형의 확률적 특성상 답변이 항상 사실에 기반한다고 확신할 수는 없다. 따라서 생성된 출력물 중에서 사용자가 비교적 손쉽게 사실관계를 파악할 수 있는 부분부터 검증을 수행하는 것이 필요하다. 아래의 예시에서는 보험수익, 당기순이익, 총자산 규모 등 정량적인 정보를 다수 포함하고 있는데 이는 원문에서도 비교적 쉽게 찾아서 사실관계를 확인할 수 있는 부분으로서 사용자가 답변의 진실성을 검증하는 데 사용할 수 있다.
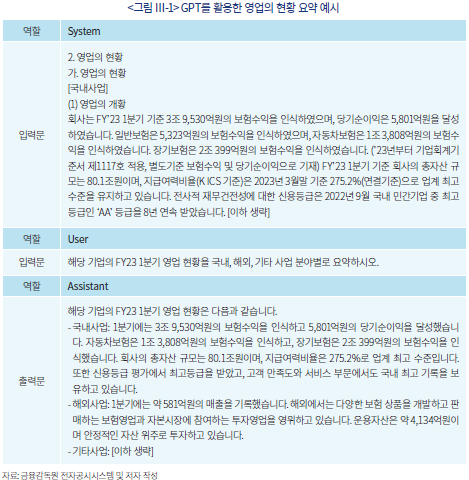
반면에 출력물에서 정성적인 정보 또는 주관적인 묘사에 대하여서는 검증에 보다 많은 시간과 노력이 소요될 수 있다. 예를 들어 요약문의 기타 사업 부분에서 “지속적인 성장”과 같은 구절은 해당 분기의 지표만으로는 평가할 수 없으며 시계열적인 분석이 바탕이 되어야 하는 명제이다. 이처럼 주어진 자료를 벗어나서 사실을 왜곡하거나 과장하는 현상은 위의 예시에 그치지 않고 지속적으로 발생하는 것으로 보인다.
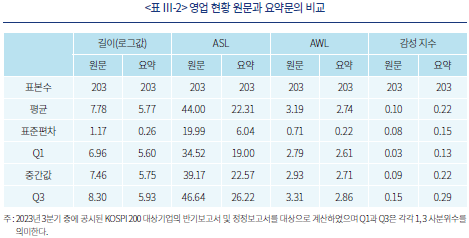
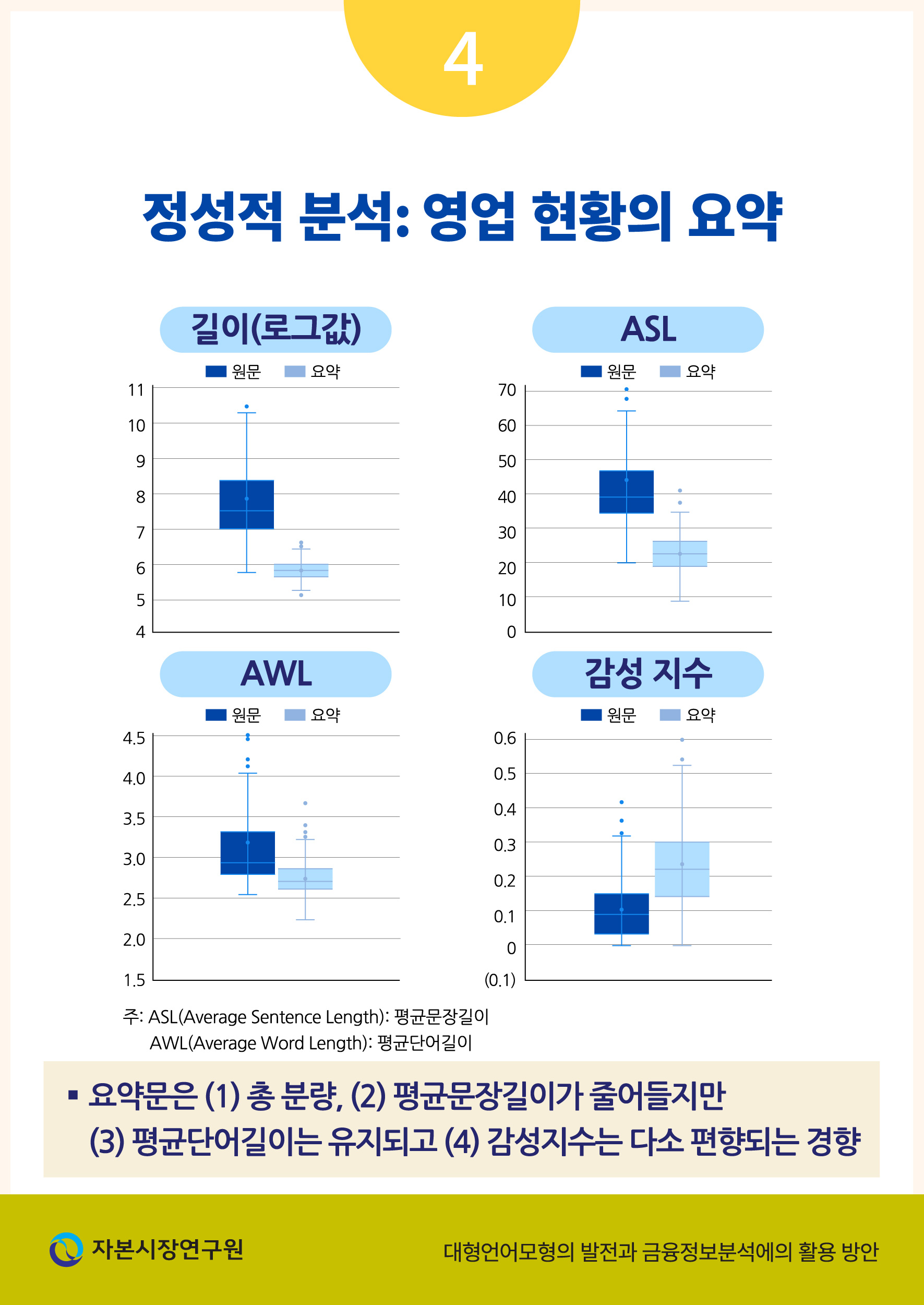
<표 Ⅲ-2>는 KOSPI 200 대상 기업의 모든 사업보고서에서 추출한 영업 현황 자료를 활용하여 위 예시와 동일한 요약 작업을 수행한 결과를 요약한 것이다. 원문과 요약문을 비교하기 위한 지표로는 다음 네 가지를 활용하였다. 우선 길이는 문서에 포함된 글자 수의 자연로그값을 나타내며 원문의 평균값인 7.78은 대략 2,400자 정도를 의미한다. 반면 요약문의 평균인 5.77은 약 320자 정도의 분량으로 요약문이 원문에 비해 약 7.5배 가량 압축된 정보를 전달하고 있음을 확인할 수 있다.
문서의 길이와 더불어 독해 난이도를 간접적으로 평가하는 지표로서 평균문장길이(Average Sentence Length: ASL)와 평균단어길이(Average Word Length: AWL)를 활용하여 원문과 요약문을 비교하였다. 여기서 평균문장길이는 하나의 문장 안에 사용된 단어의 수를 의미하며 하나의 문서에서 사용된 단어의 개수를 문장의 개수로 나눈 값이다. <표 Ⅲ-2>에서 확인할 수 있듯이 요약문은 문장당 평균 22개 단어를 사용하여, 평균적으로 44개 단어를 사용한 사업보고서 원문에 비하여 손쉽게 읽을 수 있는 정도임을 알 수 있다. 한편 평균단어길이는 문서에서 등장하는 단어의 평균적인 길이를 의미하며 글자 수를 전체 단어 수로 나눈 값으로 계산하였다. 이 지표를 기준으로 원문과 요약문을 비교하였을 때, 각각 3.19와 2.74로 큰 차이를 보이지 않아 요약문이 대체로 원문과 유사한 단어를 사용함을 간접적으로 시사하고 있다.
반면에 감정분석 지표를 비교하였을 때, 평균단어길이가 비슷하다는 점을 바탕으로 요약문이 원문의 정보를 정확히 전달하고 있다고 섣불리 결론을 내릴 수 없음을 알 수 있다. <표 Ⅲ-2>에서 제시된 감정 지수는 한글 형태소 분석 사전6)을 바탕으로 긍정적 표현과 부정적 표현에 각각 1점과 –1점을 부여하고 이를 합산한 후 문서에 등장하는 단어의 총 개수로 나눈 값을 의미한다. <표 Ⅲ-2>에서 제시된 바와 같이 사업보고서의 현황 부분 원문은 평균적으로 다소 긍정적, 또는 표준편차를 감안하였을 때 전체적으로 중립적인 문체로 작성되었음을 확인할 수 있다. 그러나 요약문은 긍정적인 의미를 지닌 단어의 비중이 상대적으로 증가하였으며 요약문 사이의 편차 또한 증가하였다. 이와 같은 결과는 GPT를 이용한 기업 현황 분석에 대한 추가적인 검증이 필수적임을 시사하고 있다.
3. 정량적 분석: 재무 지표의 분석
이 절에서는 정량적인 평가 업무로서 공시된 재무 지표를 분석하여 유용성 있는 정보를 생산하는데 대형언어모형을 활용할 수 있는 방안을 살펴보고자 한다. 금융투자업은 방대한 양의 데이터를 처리하고 해석할 수 있는 능력이 요구되어 이를 효율적으로 정리하고 유용한 정보를 빠르게 추출하는 것은 매우 중요한 과정이라고 할 수 있다. 따라서 수시로 변화하는 시장 환경에 대응하여 신속하게 거래 전략을 수립하는 절차를 대형언어모형을 통하여 보조할 수 있을 경우 업무의 효율성을 제고할 여지가 있을 것이다.
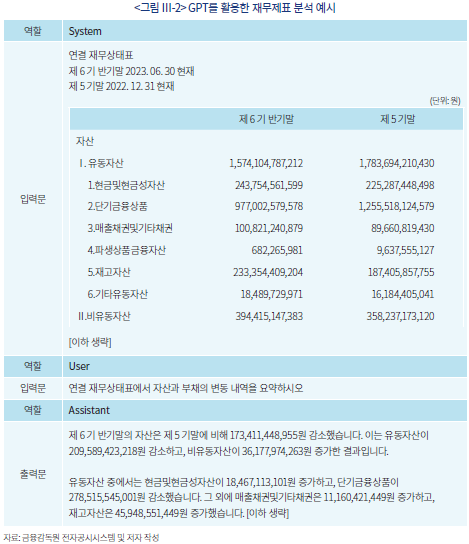
<그림 Ⅲ-2>는 GPT를 활용하여 공시된 재무제표를 분석하는 작업의 예시를 보여주고 있다. 여기서 수행하는 작업은 기초적인 단계로서 연결재무제표를 정량적으로 이해하고 중요 변동 사항을 요약하는 과제이다. 연결재무제표는 일반적으로 양이 방대하여 기업의 평가와 투자 결정을 위한 분석에 유용한 정보를 신속하게 찾아내는 과정 자체가 전문적인 지식과 더불어 많은 시간의 투입이 필요하다. 이 과정을 대형언어모형이 단축할 수 있는 하나의 사례를 위 예시가 보여주고 있다.
위 사례에서 우선 검증해야 하는 부분은 수치의 사실관계이다. 해당 사례에 한하여서는 GPT가 수량에 대한 이해 및 연산을 비교적 정확하게 수행하고 있다고 볼 수 있다. 그러나 이는 앞서 설명하였듯이 확률적인 모형에 근거하여 도출된 결과이며 연산의 결과가 아님을 상기할 필요가 있다.7)
사실관계 확인에서 나아가 GPT를 통하여 작성된 재무 정보의 분석문이 전체 재무 지표가 내포하고 있는 정보량 대비 유지 또는 손실하였는지 확인할 필요가 있다. 정보 유용성을 평가하기 위하여 공시일 주변 초과수익률(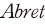 )8)과 공시일 직후 수익률 변동성(
)8)과 공시일 직후 수익률 변동성(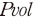 )9)이 분석문의 특성으로 설명될 수 있는지를 실증적으로 분석하고자 한다. 분석에 사용된 회귀분석 모형은 다음과 같다.
)9)이 분석문의 특성으로 설명될 수 있는지를 실증적으로 분석하고자 한다. 분석에 사용된 회귀분석 모형은 다음과 같다.
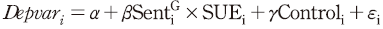
종속변수(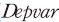 )는 초과수익률() 또는 수익률 변동성()을 의미하며 주요 설명변수로는 비기대이익(
)는 초과수익률() 또는 수익률 변동성()을 의미하며 주요 설명변수로는 비기대이익(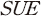 )10)을 사용하였다. 정보성 측면에서 둘 사이의 회귀계수(
)10)을 사용하였다. 정보성 측면에서 둘 사이의 회귀계수(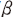 )가 클수록 수익성 지표가 내포하는 정보의 양이 큰 것을 의미한다. 이와 같은 상관관계가 분석문의 특성에 따라 어떻게 다르게 나타나는지를 살펴보기 위하여 감성지수(
)가 클수록 수익성 지표가 내포하는 정보의 양이 큰 것을 의미한다. 이와 같은 상관관계가 분석문의 특성에 따라 어떻게 다르게 나타나는지를 살펴보기 위하여 감성지수(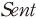 )와의 교차항을 고려하였다. 다만, 앞서 설명한 바와 같이 한국어 감성 사전의 불완전성을 고려하여 계산된 변수의 값에 따라 전체 표본을 3개의 집단(
)와의 교차항을 고려하였다. 다만, 앞서 설명한 바와 같이 한국어 감성 사전의 불완전성을 고려하여 계산된 변수의 값에 따라 전체 표본을 3개의 집단(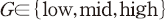 )으로 나누어 각각의 더미 변수에 대한 교차항을 사용하였다. 마지막으로 기업의 규모, 수익성, 시장가치, 부채비율, 수익성 증가율, 손실 여부, 산업 분류별 고정 효과(fixed-effect)를 통제 변수(
)으로 나누어 각각의 더미 변수에 대한 교차항을 사용하였다. 마지막으로 기업의 규모, 수익성, 시장가치, 부채비율, 수익성 증가율, 손실 여부, 산업 분류별 고정 효과(fixed-effect)를 통제 변수(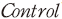 )로 사용하여 기업 특성에 의한 효과를 제한하였다.
)로 사용하여 기업 특성에 의한 효과를 제한하였다.
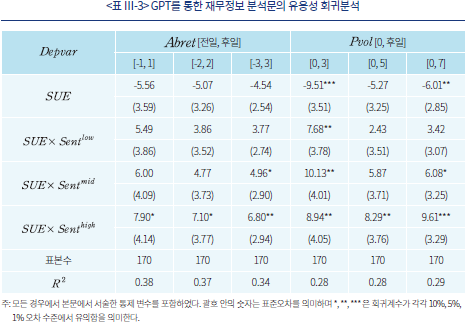
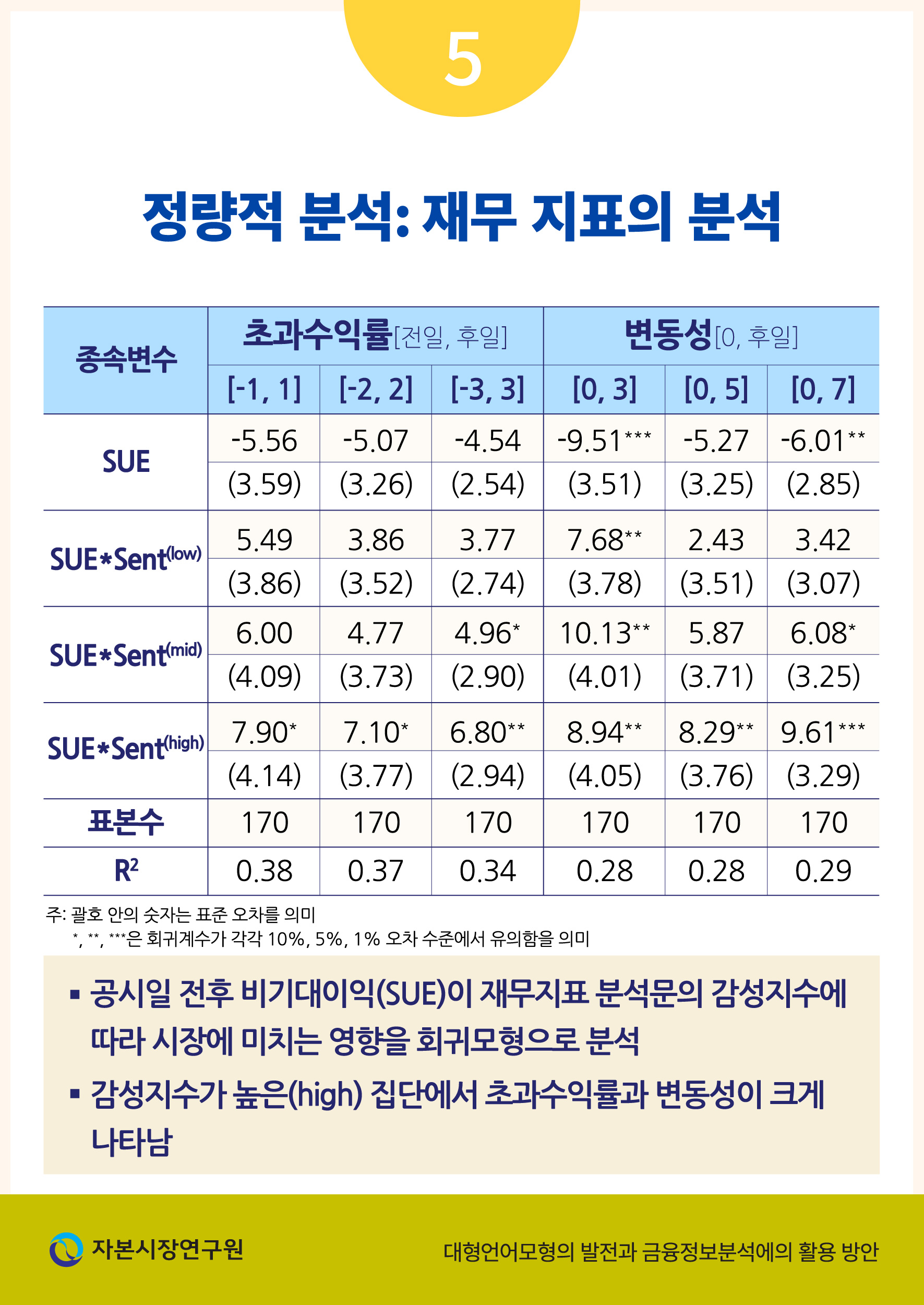
<표 Ⅲ-3>은 앞서 설명한 회귀분석 모형의 추정 결과를 보여주고 있다. 초과수익률과 수익률 변동성 모두의 경우에 대하여 비기대이익과의 상관관계가 감성지수가 높은 경우(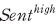 )에 더욱 크고 통계적으로 유의하게 추정되었음을 확인할 수 있다. 이는 분석문이 긍정적으로 편향된 서술일 경우에 기대이익의 차이가 시장에 빠르게 반영되었음을 의미한다고 볼 수 있다. 그러나 이와 같은 결과가 반드시 투자 수익의 증대를 의미한다고 볼 수는 없는데, 특히 공시 직후 수익률의 일일 변동성이 유의하게 증가한다는 점에서 GPT에 기반한 재무 분석이 오히려 시장에 잘못된 정보를 제공할 수도 있다는 위험 요인을 실증적으로 보여주는 결과라고 해석할 수 있다.
)에 더욱 크고 통계적으로 유의하게 추정되었음을 확인할 수 있다. 이는 분석문이 긍정적으로 편향된 서술일 경우에 기대이익의 차이가 시장에 빠르게 반영되었음을 의미한다고 볼 수 있다. 그러나 이와 같은 결과가 반드시 투자 수익의 증대를 의미한다고 볼 수는 없는데, 특히 공시 직후 수익률의 일일 변동성이 유의하게 증가한다는 점에서 GPT에 기반한 재무 분석이 오히려 시장에 잘못된 정보를 제공할 수도 있다는 위험 요인을 실증적으로 보여주는 결과라고 해석할 수 있다.
Ⅳ. 대형언어모형 활용의 위험 및 제약 요인
1. 할루시네이션 효과와 대응 방안
앞 절의 분석에서 시사하는 바와 같이 대형언어모형을 활용하여 금융정보를 분석할 경우 사실에 근거하지 않은 내용 또는 편향되거나 과장된 분석 결과를 얻을 수 있는 위험을 경계해야 한다. 이는 흔히 ‘환각’ 또는 ‘착시’로 번역되는 할루시네이션(hallucination) 현상과 밀접한 연관이 있다. 확률적인 과정에 기반하여 학습된 데이터에 포함되지 않은 출력물을 ‘생성’하는 모형의 특성상 거짓 또는 편향된 결과물을 만들 수 있는 가능성이 항상 존재하는데, 이는 언어모형의 결과물이 논리적인 사고 체계의 결과물이라는 오해와 결합하였을 때 특히 위험할 수 있다.
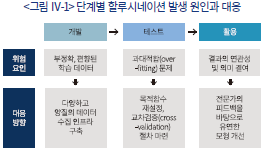
Ji et al.(2022)에서는 할루시네이션을 발생시키는 원인으로 학습 데이터의 문제와 모형의 학습 및 추론 과정의 문제를 지적하고 있다. 여기에 실무적인 활용 과정에서 발생할 수 있는 요소를 더하여 세 단계로 문제의 원인과 대응 방향을 제시하고자 한다(<그림 Ⅳ-1> 참조). 첫 번째로 학습에 사용된 데이터가 부정확하거나 편향된 정보를 포함하고 있는 경우 이를 바탕으로 개발된 모형 또한 부정확한 결과물을 생성할 수 있다. 두 번째 문제는 특정한 데이터에 지나치게 최적화된 과대적합(over-fitting) 모형의 경우 생성된 결과물이 새로운 정보를 반영하지 못하고 기존의 잘못된 정보를 답습하는 경우를 들 수 있다. 마지막으로 모형이 충분히 많은 사전 정보 또는 문맥을 동시에 고려하지 않을 경우 생성되는 답변이 문맥적인 연관성이 낮아져 무의미한 단어의 나열에 그칠 수 있다.
이와 같은 오류를 최소화하기 위해서는 다음과 같은 대응책을 고려할 수 있다. 우선, 개발 단계에서 학습에 사용될 데이터의 양적인 면과 동시에 질적인 면도 고려하여 광범위하고 지속적으로 수집할 수 있는 기반이 마련되어야 한다. 이어서 학습 및 검증 단계에서 과대적합 문제를 방지하기 위하여 적절한 목적함수를 설정하고 교차검증(cross-validation)을 강화하는 절차를 구축할 필요가 있다. 마지막으로 배포 및 사용 단계에서 금융전문가의 지식을 활용하여 결과물에 대한 피드백을 얻고 필요시 이를 바탕으로 모형을 개선할 수 있는 유연한 접근이 요구된다.11)
2. 대형언어모형 활용의 제약 요인
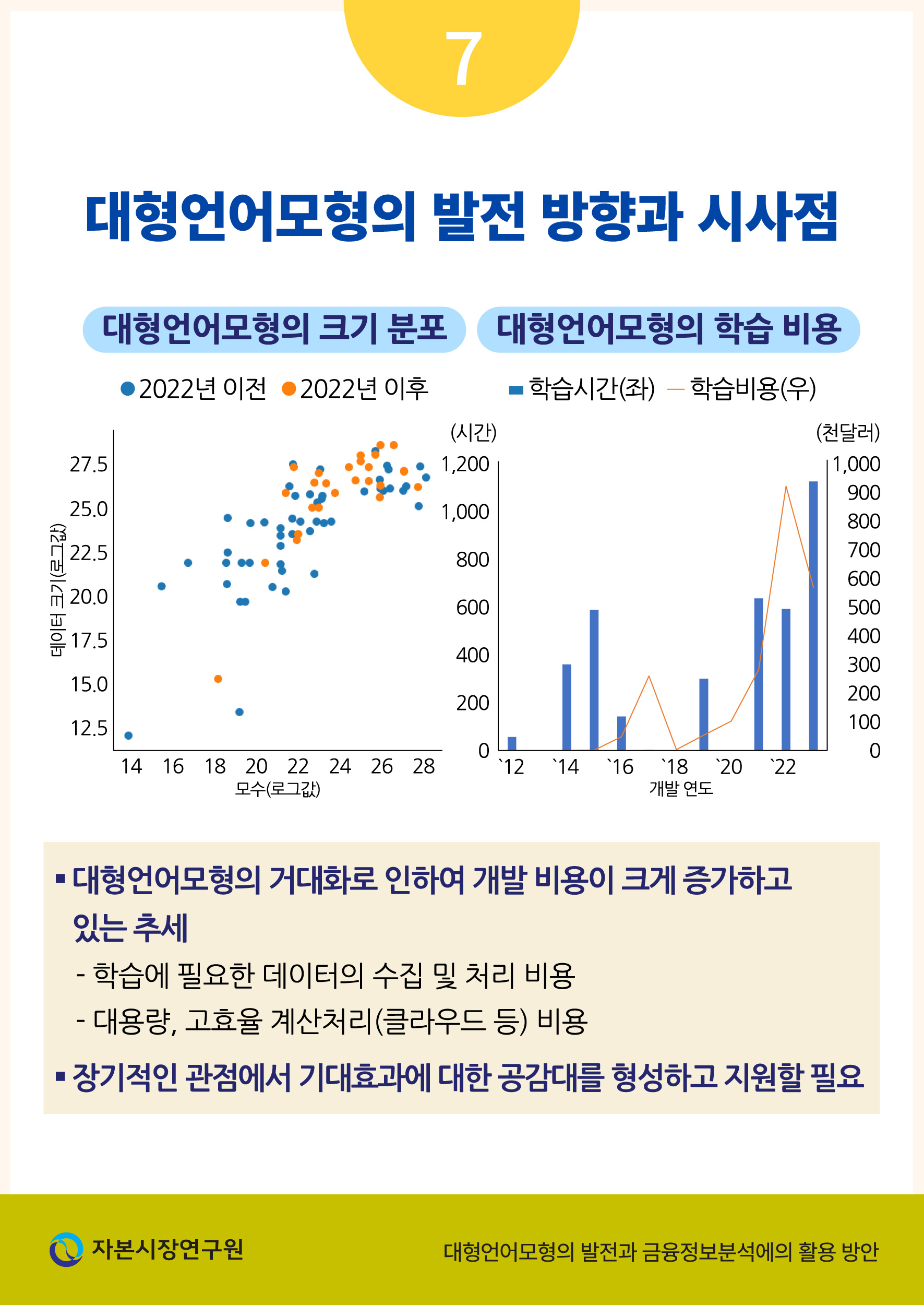
앞서 설명한 바와 같이 대형언어모형의 크기는 기하급수적으로 증가하는 추세이며 이는 동시에 모형을 학습시키는 데 필요한 비용 또한 기하급수적으로 증가하고 있음을 의미한다. <그림 Ⅳ-2>는 현재 개발 중이거나 배포된 대형언어모형들의 알려진 학습 비용이 크게 증가하고 있는 추세임을 보여주고 있다. 여기서 학습비용은 공개된 자료를 통해 추정된 값으로서 학습에 필요한 데이터를 구하는 비용, 모수를 계산하는 과정에서 사용되는 대용량 컴퓨팅(클라우드 등) 비용 등을 포함한다.
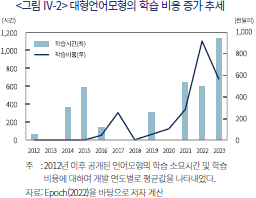
높은 개발 및 유지 비용은 금융투자업계로 하여금 대형언어모형에 대한 장기적인 투자를 주저하게 만드는 요인으로 작용할 수 있다. 특히, 비용은 상대적으로 쉽게 계산할 수 있으나 개발의 성공 여부와 기대효과에 대해서는 불확실성이 존재하는 상황에서 적극적인 변화를 추진하기 위한 공감대의 형성은 어려울 수 있다. CFA Institute는 금융투자업계가 이와 같은 불확실성 하에서 AI를 성공적으로 도입하기 위해서는 (1) AI 기술자와 금융전문가 사이의 소통과 더불어 (2) 장기적인 안목을 바탕으로 실험적인 투자를 지원하는 지도자의 역량이 필요함을 지적하였다(CFA Institute, 2021). 특히, 해당 보고서에서 제시된 성공 사례들이 모두 단기적인 성과보다 실패에서 배우는 과정을 중시했다는 점은 국내 금융투자업의 장기적인 발전 전략의 관점에서도 시사하는 바가 크다고 할 수 있다.
제도적인 제약으로서 금융투자업의 망분리 원칙은 주로 클라우드(cloud)등 원격, 고성능 컴퓨팅 설비에 기반하여 운영되는 대형언어모형의 실무적인 활용을 어렵게 하는 요인이 될 수 있다. 금융투자업은 고객의 계좌정보 등 심각한 보안 문제를 발생시킬 수 있는 정보를 다수 보유하고 있다는 점에서 현재의 클라우드에 기반한 대형언어모형의 활용이 어려운 제약이 있다. 따라서 정보 유출 위험에 노출되지 않으면서 고성능 AI 모형을 사용하는 방안으로 오픈소스(open source) 모형12)을 분리된 사내 네트워크상에서 개발 및 배포하는 방안을 고려해 볼 수 있다.
Ⅴ. 결론 및 시사점
국내 금융투자업 환경에서 대형언어모형의 성공적인 도입을 위하여 앞서 논의한 위험 및 제약 요인을 바탕으로 시사점을 크게 기술적인 면과 구조적인 면으로 나누어서 제시하고자 한다. 기술적인 차원에서는 높은 품질의 학습 데이터를 지속적으로 수집 및 활용할 수 있는 인프라의 구축이 선결과제라고 할 수 있다. 대형언어모형이 신뢰성 높은 결과물을 생성하기 위한 필수적인 전제조건은 대규모의 문헌 자료를 지속적으로 학습하고 그 과정에서 모수를 업데이트하는 개발 절차의 확립일 것이다. 따라서 양질의 언어 데이터를 꾸준히 그리고 적시에 공급할 수 있는 역량은 모형의 활용도와 직결되는 문제이다.
이와 같은 문제의식에 기반하여 금융투자업에서 언어모형을 개발 및 활용하기 위하여 사용할 수 있는 데이터의 종류를 생각해 볼 때, 유의미한 개선점을 도출할 수 있을 것이다. 일례로 본 고의 분석에서 사용된 사업보고서 데이터의 경우 금융감독원의 전자공시 시스템(DART)에서 제공하는 Open API를 활용하여 수집 및 처리할 수 있다. 하지만 문서 내에서 종종 발견되는 특수문자 및 영문, 한문 등 외래어의 일관되지 않은 용법은 특정 기업의 시계열적 분석뿐만 아니라 기업 사이의 비교를 위하여 대량의 보고서를 일괄적으로 처리하는 작업을 어렵게 하는 요소로서 작용할 수 있다. 이와 관련하여 XBRL 등 표준화된 공시 양식의 도입 등의 논의가 이루어지고 있는 점은 향후 기업 정보의 일괄적인 처리를 위한 인프라 구축 가능성과 이를 기반으로 한 신뢰성 있는 대형언어모형의 개발에 긍정적인 요소일 것이다.
구조적인 면에서 초거대 AI 모형을 개발 및 유지에 대한 관심이 제고되어야 할 것이다. 국내 금융투자업의 IT 역량의 척도로서 인적, 물적 자원의 집약도는 같은 분야의 글로벌 선도 기업과 비교하였을 때 크게 부족한 것으로 파악되고 있다(이효섭, 2023. 3. 14; 노성호, 2023). 이와 같은 상황에 비추어 보았을 때, 대형언어모형과 같은 첨단의 AI 기술을 활용하여 금융투자업의 장기적인 발전 동력을 마련하기 위해서는 최근 급격히 증가한 관심도가 개발 역량 및 기술 인프라에 대한 투자로 치환될 수 있도록 관심과 지원이 필요할 것이다.
1) 학습 데이터의 발전은 비단 양적인 면에서만 이루어진 것이 아니라 서로 다른 형태의 자료를 종합적으로 학습하는 멀티모달(multimodal) 모형으로 발전하고 있으며, 일례로 문서와 그림 정보를 동시에 학습한 Swin Transformer를 들 수 있다(Liu et al., 2021).
2) 대형언어모형을 활용할 때 사용자와의 짧은 문답을 통해 학습 데이터에 포함되지 않은 답변을 생성하도록 유도하는 과정을 프롬프트 엔지니어링(prompt engineering)이라고 한다. 이에 대해서는 Ⅲ-1.장에서 자세히 설명하고 있다.
3) 이처럼 중첩적인 학습 과정을 거치는 신경망 모형을 가리켜 Recurrent Neural Network(RNN) 이라고 한다. 이중 특히 불필요한 ‘기억’을 단계별로 점차 삭제해서 학습의 효율을 높인 형태가 Long-Short Term Memory(LSTM) 모형이다.
4) 이러한 특성은 거짓 정보를 마치 사실인 양 출력하는 이른바 할루시네이션(hallucination) 효과와 밀접하게 연관되어 있다. 할루시네이션의 정의와 대응 방안에 대해서는 다음 절에서 보다 자세히 설명하고자 한다.
5) OpenAI에서 공식적으로 제안하는 프롬프트 엔지니어링 방식은 다음 사이트에서 찾을 수 있다. https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
6) 이 연구에서는 KNU 한국어 감성사전(http://dilab.kunsan.ac.kr/knusl.html)을 분석 기준으로 사용하였다. 다만, 해당 사전은 금융 전문 용어에 대한 보완이 이루어지지 않은 일반적인 용법에 근거한 사전이며, 금융 전문 용어에 대한 추가적인 분석은 조수지ㆍ김흥규ㆍ양철원(2021) 등이 있다.
7) 실제로 간단한 방정식의 해를 구하는 문제에서도 추가적인 학습이 없을 경우 GPT-3는 첫 시도에서 약 31% 정도의 낮은 정답률을 나타낼 수 있다(Zong & Krishnamachari, 2023).
8) 개별종목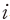 의 초과수익률은 다음과 같이 계산하였다.
의 초과수익률은 다음과 같이 계산하였다. 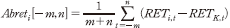 여기서
여기서 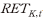 는 KOSPI 200 지수의 일간 총수익률을 의미한다.
는 KOSPI 200 지수의 일간 총수익률을 의미한다.
9) 개별종목의 수익률 변동성은 다음과 같이 계산하였다. 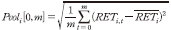 여기서
여기서 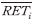 는 같은기간 동안의 종목 의 평균수익률을 의미한다.
는 같은기간 동안의 종목 의 평균수익률을 의미한다.
10) 비기대이익은 랜덤워크 가정에 근거하여 이번기의 주당순이익(EPS)과 지난기의 주당순이익의 차이로 계산하였다.
11) 이와 같은 절차를 흔히 Human-In-The-Loop(HITL)이라고 한다.
12) 이를테면 Meta에서 개발 및 배포하고 있는 LLaMA의 경우 오픈소스로 제공되어 외부망에 접속하지 않은 환경에서도 개발 및 사용이 가능하여 학습 과정에 대한 투명성이 제고될 뿐만 아니라 학습에 사용된 데이터가 조직 외부로 유출되는 상황을 방지할 수 있다.
참고문헌
노성호, 2023, 『금융산업에서의 인공지능(AI) 활용 방안에 따른 리스크 요인 분석』, 자본시장연구원 이슈보고서 23-13.
노성호, 2023, 생성형 AI에 의한 생산성 혁신과 금융업의 대응 방향, 자본시장연구원 『자본시장포커스』 2023-18호.
서범석ㆍ이영환ㆍ조형배, 2022, 『기계학습을 이용한 뉴스심리지수(NSI)의 작성과 활용』, 국민계정리뷰.
이효섭, 2023. 3. 14, 해외 IB의 발전전략 및 한국형 IB의 과제, 금융투자업의 글로벌 경쟁력 강화 방안 세미나 발표자료.
이효섭, 2023, 생성형 AI가 금융산업에 미치는 영향 – 혁신과 리스크요인, 『글로벌금융리뷰』 제4권 1호.
조수지ㆍ김흥규ㆍ양철원, 2021, 기업 재무분석을 위한 한국어 감성사전 구축, 『한국증권학회지』 제50권 2호.
Baily, M.N., Brynjolfsson, E., Korinek, A., 2023. 5. 10, Machines of mind: The case for an AI-powered productivity boom, Brookings Commentary.
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J. Q., Demszky, D., Donahue, C., Doumbouya, M., Durmus, E., Ermon, S., Etchemendy, J., Ethayarajh, K., Fei-Fei, L., Finn, C., Gale, T., Gillespie, L., Goel, K., Goodman, N., Grossman, S., Guha, N., Hashimoto, T., Henderson, P., Hewitt, J., Ho, D.E., Hong, J., Hsu, K., Huang, J., Icard, T., Jain, S., Jurafsky, D., Kalluri, P., Karamcheti, S., Keeling, G., Khani, F., Khattab, O., Koh, P.W., Krass, M., Krishna, R., Kuditipudi, R., Kumar, A., Ladhak, F., Lee, M., Lee, T., Leskovec, J., Levent, I., Li, X.L., Li, X., Ma, T., Malik, A., Manning, C.D., Mirchandani, S., Mitchell, E., Munyikwa, Z., Nair, S., Narayan, A., Narayanan, D., Newman, B., Nie, A., Niebles, J.C., Nilforoshan, H., Nyarko, J., Ogut, G., Orr, L., Papadimitriou, I., Park, J.S., Piech, C., Portelance, E., Potts, C., Raghunathan, A., Reich, R., Ren, H., Rong, F., Roohani, Y., Ruiz, C., Ryan, J., Re, C., Sadigh, D., Sagawa, S., Santhanam, K., Shih, A., Srinivasan, K., Tamkin, A., Taori, R., Thomas, A.W., Tramer, F., Wang, R.E., Wang, W., Wu, B., Wu, J., Wu, Y., Xie, S.M., Yasunaga, M., You, J., Zaharia, M., Zhang, M., Zhang, T., Zhang, X., Zhang, Y., Zheng, L., Zhou, K., Liang, P., 2021, On the opportunities and risks of foundation models, arXⅣ preprint arXⅣ:2108.07258.
CFA Institute, 2021, T-Shaped Teams: Organizing to Adopt AI and Big Data at Investment Firms.
Eloundou, T., Manning, S., Mishkin, P., Rock, D., 2023, GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models, Working Paper.
Epoch, 2022, Parameter, Compute and Data Trends in Machine Learning https://epochai.org/data/pcd
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., IshⅡ, E., Bang, Y., Dai, W., Madotto, A., Fung, P., 2022, Survey of Hallucination in Natural Language Generation, ACM Computing Surveys. Association for Computing Machinery 55 (12), 1–38.
Kim, A., Muhn, M., Nikolaev, V., 2023, Bloated Disclosures: Can ChatGPT Help Investors Process Financial Information? arXⅣ preprint arXⅣ:2306.10224.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B., 2021, Swin Transformer: Hierarchical Vision Transformer using Swifted Windows, arXⅣ preprint arXⅣ:2103.14030.
Luong, M.T., Pham, H., Manning, C.D., 2015, Effective approaches to attention-based neural machine translation, arXⅣ preprint arXⅣ:1508.04025.
McKinsey Global Institute, 2023, The economic potential of generative AI: The next productivity frontier.
Sevilla, J., Heim, L., Ho, A., Besiroglu, T., Hobbhahn, M., Villalobos, P., 2022, Compute trends across three eras of machine learning, 2022 International Joint Conference on Neural Networks (IJCNN), IEEE 1-8.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2017, Attention is all you need, Advances in neural information processing systems, 30.
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., Mann, G., 2023, Bloomberggpt: A large language model for finance. arXⅣ preprint arXⅣ:2303.17564.
Yang, H., Liu, X.Y., Wang, C.D., 2023, FinGPT: Open-Source Financial Large Language Models. arXⅣ preprint arXⅣ:2306.06031.
Zong, M., Krishnamachari, B., 2023, Solving math word problems concerning systems of equations with gpt-3, Proceedings of the AAAI Conference on Artificial Intelligence 37(13), 15972-15979.
Statista https://www.statista.com/chart/29174/time-to-one-million-users/
수많은 웹 기반 서비스 중에서도 생성형 AI(Generative AI)만큼 급격하게 대중의 관심을 얻은 사례는 찾기 어려울 것이다. OpenAI가 제공하는 생성형 AI 기반 언어모형의 대표주자인 ChatGPT는 최단기간 안에 100만 사용자를 돌파한 바 있다(<표 Ⅰ-1> 참조, 2023년 6월 기준). 이와 같은 폭발적인 인기의 이면에는 생성형 AI의 활용 가능성에 대한 기대와 오해가 공존하고 있다. 이에 본 고에서는 생성형 AI의 일종으로서 폭넓은 적용 가능성을 보인 대형언어모형(Large Language Model: LLM)의 기반 기술을 설명하고 예시를 바탕으로 금융정보분석에의 활용 방안을 모색하고자 한다.
ChatGPT의 대중적인 관심은 흥미의 단계를 넘어서 생성형 AI를 활용한 생산성 혁신의 가능성을 논의하는 단계로 접어들고 있다. 글로벌 컨설팅 기업 McKinsey & Company의 연구보고서는 생성형 AI의 확산이 여러 산업 분야에 걸쳐 약 2.6조달러에서 4.4조달러의 가치를 새롭게 창출할 것으로 예상하였다(McKinsey Global Institute, 2023). 생성형 AI가 이처럼 큰 파급 효과를 불러올 수 있었던 이유로는 크게 두 가지를 지적할 수 있다. 첫 번째는 기술의 범용성으로서, 거대한 규모에서 나오는 의외성(혹은 창의성)을 바탕으로 모형을 다양한 산업군과 업무 분야에 맞춤화(customize)할 수 있다. 이는 향후 미국 내 약 80% 정도의 직업군에서 생성형 AI를 사용하게 될 것이라는 Eloundou et al.(2023)의 예측과도 일치하는 것이다. 두 번째 이유는 생성형 AI가 기존의 혁신 기술과 달리 인지적(cognitive) 능력을 보조하는 도구로 개발되었다는 점이다. Baily et al.(2023)의 연구에서 확인되었듯이, 생성형 AI는 주로 고소득 직업에서 요구되는 프로그래밍, 작문, 연구 등의 고부가가치 업무를 보조할 수 있다.
생성형 AI 및 대형언어모형을 경제ㆍ금융정보 분석에 적용하는 연구 또한 진행되고 있다. 서범석ㆍ이영환ㆍ조형배(2022)는 뉴스 기사의 경기에 대한 심리적 기대감을 지수화하는 모형을 개발하였으며, Kim et al.(2023)은 사업보고서에서 유용한 정보를 추출하는데 GPT를 활용하는 방안에 대한 실증분석을 진행하였다. 최근에는 금융 분석 전반에 사용될 수 있는 범용 언어모형을 개발하려는 노력 또한 진행되고 있다(Yang et al., 2023; Wu et al., 2023).
생성형 AI의 효용에 대한 낙관적인 기대는 금융산업 여러 분야에서 실험적인 도입으로 이어지고 있으나(이효섭, 2023), 실무적인 차원에서의 확산을 어렵게 하는 요소 또한 존재하고 있다. 모형 내적인 요소로는 기존에 없는 정보를 생성하는 과정에서 근거가 부족하거나 거짓인 내용을 마치 사실처럼 서술하는 할루시네이션(hallucination) 문제를 지적할 수 있다. 이와 더불어 초거대 AI 모형을 개발하고 적용하는 데 필요한 비용이 급격하게 증가하고 있어 부담으로 작용할 수 있다.
이와 같은 문제의식을 바탕으로 본 고에서는 대형언어모형의 운용 원리를 분석하고, 실무적 활용 방안과 더불어 그 과정에서 발생 가능한 문제점들에 대한 대응 방향을 제시하고자 한다. 제Ⅱ장에서는 생성형 AI의 기반 구조와 발전 과정을 소개하고 대형언어모형의 작동 원리를 설명하였다. 제Ⅲ장에서는 대형언어모형을 활용하여 금융정보를 분석하는 방안과 그 효용성을 실증적으로 평가하였다. 제Ⅳ장에서는 앞서 설명된 활용 방안과 관련하여 예상되는 리스크 요인을 분석하고 대응책을 제시하였다. 마지막으로 제Ⅴ장에서는 국내 금융투자업 환경에서 대형언어모형의 개발 및 적용에 있어서 시사점과 개선 방향을 논의하였다.
Ⅱ. 생성형 AI(Generative AI)와 언어모형의 이해
생성형 AI는 포괄적인 의미에서 사용자가 입력한 프롬프트(prompt)에 따라 문자, 음성, 그림, 동영상 등 다양한 형태의 컨텐츠를 작성하는 AI 모형으로 정의할 수 있다. 생성형 AI의 기반이 되는 기술은 Vaswani et al.(2017)의 논문에서 처음 제안된 트랜스포머(transformer)로 볼 수 있다. 해당 논문은 트랜스포머 구조에 기반한 언어모형이 대규모의 데이터를 순차적으로 학습하여 영어-독일어 번역 문제에서 두 언어에 능통한 인간과 유사한 결과를 만들어 낼 수 있음을 보여준 바 있다. 생성형 AI의 기술적 특징으로서 이처럼 확률적인 답을 순차적으로 ‘생성(generate)’하는 구조는 마치 인간이 새로운 문장을 ‘창작(create)’하는 것과 유사하게 보인다는 점에서 큰 주목을 받고 있다.
1. 파운데이션 모형(Foundation Model)과 생성형 AI의 발전
생성형 AI의 개발 배경을 이해하기 위해서는 현재 널리 활용되고 있는 파운데이션 모형(foundation model)이 최근 AI의 발전 과정에서 차지하는 위상을 논의할 필요가 있다. Bommasani et al.(2022)은 광범위한 데이터를 바탕으로 학습된 초거대 AI가 다양한 목적에 대하여 기반이 되는 모형으로 쓰일 수 있다는 점에 착안하여 이를 파운데이션 모형이라고 지칭하였다. 나아가, 생성형 AI가 탄생하기까지의 과정을 세분화하여 크게 세 가지의 기술 발전 단계–머신러닝(machine learning), 딥러닝(deep learning), 그리고 파운데이션 모형(foundation model)–으로 나누어 설명하였다. <그림 Ⅱ-1>에서는 각 단계의 기술이 AI의 발전 과정에서 상징하는 바를 기술적 과제의 대두와 그에 대한 대응을 중심으로 나타내었다.
우선 머신러닝의 발전은 모형을 어떻게 학습시킬 것인지에 대한 방법론적인 과제의 대두에서 비롯되었으며 이는 학습 모형의 통합이라는 결과를 가져오게 된다. 이는 머신러닝 방법론이 성숙기에 접어든 시점에서 데이터를 학습하는 방식을 일원화하였다는 점에서 그 의미를 찾을 수 있다. 두 번째 발전 단계에서 딥러닝의 등장은 학습에 필요한 특성(feature)의 선정에 대한 고민에서 비롯하였으며 이를 통하여 모형의 구조(architecture)에 대한 일관된 접근을 가능하게 하였다. 마지막으로 파운데이션 모형의 등장은 앞서 머신러닝, 딥러닝 방법을 바탕으로 구축된 모형의 기능성(functionality)에 대한 고민에서 출발하였다고 볼 수 있다. 이에 대한 해답으로서 초거대 규모의 신경망에 기반한 파운데이션 모형은 범용성을 바탕으로 실무적인 차원에서 어떤 모형을 사용할지에 대한 (현재까지) 최선의 방안을 제시하였다고 평가할 수 있다.
파운데이션 모형이 이와 같은 범용성을 나타낼 수 있게 된 주원인은 학습 데이터의 양적인 성장과 이를 학습시킬 수 있을 정도로 모형이 대형화된 것에서 찾을 수 있다. 최근 개발된 AI 모형들의 크기는 최근 더욱 급격하게 증가하고 있으며 동시에 모형이 학습할 수 있는 데이터의 규모 또한 과거에 개발된 AI 모형에 비해 매우 방대해지고 있다.1) 이와 같은 거대화 추세에 대하여 Sevilla et al.(2022)은 AI의 대형화 과정을 세 단계로 나누어서 설명하였다. 첫 번째 발전 단계는 딥러닝이 널리 사용되기 이전 단계로서 대략적으로 2010년 이전에 개발된 AI 모형들을 포함한다. 2010년 이후 딥러닝이 보편화되는 과정에서 모형의 크기는 폭발적으로 증가하고 있음을 해당 연구를 통해 분석하였다. 다음 발전 단계는 2015년 알파고(AlphaGo)의 개발을 기점으로 대형화 기조가 더욱 강화된 점을 지적하고 있다. 이와 같은 추세는 지속적으로 이어져 <그림 Ⅱ-2>에서 확인할 수 있듯이 초거대 언어모형들이 최근 더욱 집중적으로 개발되고 있다.
이처럼 방대한 자료를 학습한 파운데이션 모형은 그 거대함과 복잡함을 바탕으로 예상을 벗어나 주어진 문맥을 실시간으로 학습하는 양상을 보인다. 흔히 In-Context Learning(ICL)기능2)을 통하여 파운데이션 모형은 학습된 자료를 벗어나 마치 새로운 정보를 ‘생성(generate)’하는 것 같은 기능을 선보이게 된다. 예를 들어 GPT는 문학 작품을 만들고, 사용자의 지시에 따라 기존에 없던 그림을 그리며, 작곡을 하기도 한다. 이처럼 마치 창작에 가까운 과정을 통해 기존에 없던 자료를 만들어 내는 단계에 이른 AI 모형들로 인하여 생성형 AI의 개념이 대두하게 되었다.
2. 대형언어모형의 구조
모든 AI 기반 모형이 그렇듯 생성형 AI 또한 머신러닝 알고리즘을 바탕으로 방대한 양의 자료에서 다양한 연관관계 및 패턴을 학습하여 매개변수(parameter)를 계산한다. 여기서 흔히 사용되는 모형은 다층적인 신경망(neural network), 또는 딥러닝 모형이 사용되며 이는 기존의 딥러닝 기반 AI와 동일한 점이다. 그러나 전통적인 AI의 학습 과정이 일회성이고 정태적인 반면 생성형 AI는 지난 학습 과정에서의 출력물이 다음 학습 단계에서의 입력 정보가 되는 동태적, 중첩적인 과정을 거쳐 최종 결과물이 생성된다는 차이가 있다.3)
트랜스포머 구조의 중첩적인 처리 과정은 번역에 특화된 언어모형의 예시를 통해 쉽게 이해할 수 있다. <그림 Ⅱ-3>은 영어 문장을 한국어로 번역하는 트랜스포머 모형을 간략하게 표현한 것이다. 전처리 과정에서 텐서로 표현된 각 영어 단어는 미리 학습된 가중치를 곱하여 컨텍스트 벡터(context vector)를 형성하게 된다. 이와 더불어 텐서로 표현된 한국어 어휘 사이의 관계망을 다차원 행렬로 표현한 것이 어텐션(attention) 구조이다. 이와 같은 계산 과정을 통해 만들어진 출력문은 입력된 문장 전체를 참조할 뿐만 아니라 직전에 출력된 단어 또한 참조해서 최종 결과물을 산출하게 된다.
번역의 예시에서도 알 수 있듯이, 기존의 AI 모형들과 대비되는 생성형 AI의 특징으로 비전문가가 대부분을 차지하는 사용자(end user)가 직접 생성된 정보를 소비한다는 점을 들 수 있다. 따라서 다른 AI 응용 사례와 비교하였을 때 입력자료의 인코딩(encoding)과 더불어 출력 자료의 디코딩(decoding)이 중요해지고 있다.
3. 금융투자업에서의 언어모형 활용 방안
생성형 AI의 도입에 있어서 금융산업은 다른 산업군에 비하여 투자 규모면에서 상위권에 위치하고 있다(노성호, 2023). 특히, 최근 금융산업에서의 생성형 AI 활용 사례들은 챗봇을 활용한 고객 지원, 로보어드바이저(robo advisor)를 활용한 자산관리 효율화, 이상 거래 탐지 등 컴플라이언스 강화 등 다양한 업무 분야에 걸쳐서 나타나고 있다(이효섭, 2023). 이와 같은 사례에서 나아가 금융산업의 세부 분야로서 금융투자업에서 언어모형을 활용할 수 있는 방안을 앞 절에서 소개한 모형의 특성이 비추어 구체화하고자 한다.
<표 Ⅱ-1>에서는 금융투자업의 여러 업무 분야 중 기업금융, 자산관리, 고객관리 측면에서 언어모형을 활용할 수 있는 방안에 대한 예시를 간략하게 제시하였다. 우선, 영업 현황에 대한 정보를 포함하고 있는 문자 정보를 학습한 언어모형을 기업 평가에 활용하는 방안을 고려할 수 있다. 학습된 자료의 정보적 연관성이 충분하다는 전제하에 이와 같은 모형을 통해 작성된 보고서는 다면적인 정보를 요약하여 기업 가치 평가 업무를 보조할 수 있다. 한편, 방대한 양의 경제 동향 관련 뉴스를 종합적으로 학습하고 필요한 정보를 요약하는 업무 또한 언어모형의 보조를 통해 효율성을 제고할 수 있다. 마지막으로 이미 금융업 여러 분야에서 활용하고 있는 고객 상담용 챗봇 또한 대형언어모형을 활용하여 정해진 답변에서 나아가 고객 정보와 시장 동향에 부합하는 답을 생성하는 방향으로 개선할 수 있을 것이다.
Ⅲ. 금융정보분석에서의 대형언어모형 활용 방안
1. 실무에서의 활용을 위한 맞춤화(customization) 방식
앞 절에서 설명한 바와 같이 파운데이션 모형에 기초한 대형언어모형의 가장 큰 장점은 대량의 정보를 미리 학습하여 추가적인 개량이 없이도 비교적 넓은 범위의 작업에 즉시 사용이 가능하다는 점이다. 그러나 실무적인 차원에서는 범용성을 가진 일반 모형보다는 목적에 부합하는 데이터를 추가로 학습시켜 맞춤화(customize)한 모형이 더 큰 활용성을 보일 수 있다.
대형언어모형의 맞춤화 과정은 일반적으로 두 가지 방식을 통하여 이루어진다(<표 Ⅲ-1> 참조). 첫 번째로 프롬프트 엔지니어링(prompt engineering)은 사용자와의 (비교적) 짧은 문답을 통해 모형으로 하여금 추가적인 정보 또는 문맥에 맞는 답변 방식을 학습하고 이에 따라 개선된 결과를 제시하도록 유도하는 과정을 의미한다. 이와 같은 접근방식은 사용자가 달성하고자 하는 목적이 명확할수록 이를 모형이 비교적 빠르게 학습하는 장점이 있다.
두 번째로 미세조정(fine-tuning)은 앞서 설명한 프롬프트 엔지니어링과는 다르게 대량의 정보를 일괄적으로 학습시켜 모형의 구조, 특히 신경망 사이의 가중치를 변경하는 방식을 의미한다. 이 과정에서 모형은 지도학습(supervised learning) 방식으로 매개변수 및 가중치를 재조정하게 되며, 따라서 원하는 작업 또는 주제와 관련되었을 뿐만 아니라 레이블이 지정된 데이터가 필수적으로 사용된다. 더불어 거대한 모형을 다시 계산하는 과정이 필요한 만큼 개발 및 테스트에 많은 시간과 노력이 필요할 수 있다.
근래에 들어 GPT와 같은 대형언어모형을 실무에서 활용하기 위한 사전 조율 단계에서 미세조정보다는 프롬프트 엔지니어링을 통해 사용자가 개입하는 접근방식이 그 효율성을 인정받아 널리 활용되고 있다. 이 중 특히 언어모형에 적용되는 방식인 ICL은 비용 및 시간이 많이 들어가는 미세조정 방식 대비 효율이 높을 뿐만 아니라 대량의 말뭉치(corpus) 데이터에서 흔히 발견될 수 있는 문제인 허위 관계(spurious correlation)를 학습할 가능성을 낮춘다는 장점이 있다.
2. 정성적 분석: 공시 정보의 요약 및 추출
이 장에서는 앞서 설명한 대형언어모형의 구조와 활용 방식에 대한 이해를 바탕으로 금융정보의 분석에 활용할 수 있는 방안을 제시하고 그 효과를 분석하고자 한다. 예시에 사용된 모형은 흔히 ChatGPT로 알려진 GPT-3.5-turbo를 바탕으로 프롬프트 엔지니어링을 통해 보다 유용한 정보를 생성할 수 있도록 개선한 형태이다. 학습 자료는 KOSPI 200 기업의 반기보고서와 이에 상응하는 재무 지표를 활용 목적에 따라 선택적으로 사용하였다.
길고 복잡한 사업보고서와 재무제표를 요약하고 이해하는 과정은 기업의 가치를 평가하는 데 있어서 중요한 기초작업이지만 일반적으로 상당한 시간과 노력이 투입될 수 있다. 따라서 간단한 명령문을 활용하여 정보를 효율적으로 요약하는 방법을 살펴보고자 한다. <그림 Ⅲ-1>은 국내 대형 보험사의 2023년 1분기 영업 현황을 GPT로 요약하는 예시이다. 첫 번째 작업은 앞 절에서 설명한 ICL에 해당하는 단계로서 분석의 기반이 되는 자료를 모형에 사전적으로 학습(입력)시키는 것이다. 이는 아래 예시에서 system 역할에 반기보고서 중 영업의 현황 항목을 입력한 것을 의미한다. GPT는 사전에 학습된 트랜스포머 구조에 기반하므로 최신의 정보를 반영하고 있지 않으며, 따라서 이와 같은 학습 과정이 선행되지 않으면 사실에 근거한 답변을 기대할 수 없다.4) 이를 보완하기 위하여 사용자가 직접 목적에 부합하는 자료를 GPT에 제공하는 과정이 선행되었을 때 적어도 기초적인 사실관계에서 크게 벗어나지 않는 답변을 기대할 수 있다.
분석의 두 번째 요소는 사용자가 입력하는 명령이다. OpenAI에서 제안한 GPT의 올바른 활용 방안에 따르면 명령문이 구체적이고, 예시와 함께 작성되었을 때 보다 효과적인 답변을 기대할 수 있다.5) 아래의 예시에서는 명령문을 작성하는 과정에서 영업의 현황을 국내, 해외, 그리고 기타 사업 분야로 나누어 설명할 것을 주문하였다. 따라서 답변 또한 system 프롬프트에서 제공된 대량의 정보에서 명령문에 포함된 세 분야에 높은 비중을 부여하여 요약 과정에서 발생할 수 있는 정보의 무작위적 손실을 줄일 수 있다.
마지막 단계이자 GPT 활용의 가장 중요한 과정으로서 출력된 답변에 대한 검증 또한 필요하다. 사전 학습과 구체적이고 유의미한 명령문 작성의 단계를 통하여 답변의 정확도를 높일 수 있으나, 언어모형의 확률적 특성상 답변이 항상 사실에 기반한다고 확신할 수는 없다. 따라서 생성된 출력물 중에서 사용자가 비교적 손쉽게 사실관계를 파악할 수 있는 부분부터 검증을 수행하는 것이 필요하다. 아래의 예시에서는 보험수익, 당기순이익, 총자산 규모 등 정량적인 정보를 다수 포함하고 있는데 이는 원문에서도 비교적 쉽게 찾아서 사실관계를 확인할 수 있는 부분으로서 사용자가 답변의 진실성을 검증하는 데 사용할 수 있다.
반면에 출력물에서 정성적인 정보 또는 주관적인 묘사에 대하여서는 검증에 보다 많은 시간과 노력이 소요될 수 있다. 예를 들어 요약문의 기타 사업 부분에서 “지속적인 성장”과 같은 구절은 해당 분기의 지표만으로는 평가할 수 없으며 시계열적인 분석이 바탕이 되어야 하는 명제이다. 이처럼 주어진 자료를 벗어나서 사실을 왜곡하거나 과장하는 현상은 위의 예시에 그치지 않고 지속적으로 발생하는 것으로 보인다.
<표 Ⅲ-2>는 KOSPI 200 대상 기업의 모든 사업보고서에서 추출한 영업 현황 자료를 활용하여 위 예시와 동일한 요약 작업을 수행한 결과를 요약한 것이다. 원문과 요약문을 비교하기 위한 지표로는 다음 네 가지를 활용하였다. 우선 길이는 문서에 포함된 글자 수의 자연로그값을 나타내며 원문의 평균값인 7.78은 대략 2,400자 정도를 의미한다. 반면 요약문의 평균인 5.77은 약 320자 정도의 분량으로 요약문이 원문에 비해 약 7.5배 가량 압축된 정보를 전달하고 있음을 확인할 수 있다.
문서의 길이와 더불어 독해 난이도를 간접적으로 평가하는 지표로서 평균문장길이(Average Sentence Length: ASL)와 평균단어길이(Average Word Length: AWL)를 활용하여 원문과 요약문을 비교하였다. 여기서 평균문장길이는 하나의 문장 안에 사용된 단어의 수를 의미하며 하나의 문서에서 사용된 단어의 개수를 문장의 개수로 나눈 값이다. <표 Ⅲ-2>에서 확인할 수 있듯이 요약문은 문장당 평균 22개 단어를 사용하여, 평균적으로 44개 단어를 사용한 사업보고서 원문에 비하여 손쉽게 읽을 수 있는 정도임을 알 수 있다. 한편 평균단어길이는 문서에서 등장하는 단어의 평균적인 길이를 의미하며 글자 수를 전체 단어 수로 나눈 값으로 계산하였다. 이 지표를 기준으로 원문과 요약문을 비교하였을 때, 각각 3.19와 2.74로 큰 차이를 보이지 않아 요약문이 대체로 원문과 유사한 단어를 사용함을 간접적으로 시사하고 있다.
반면에 감정분석 지표를 비교하였을 때, 평균단어길이가 비슷하다는 점을 바탕으로 요약문이 원문의 정보를 정확히 전달하고 있다고 섣불리 결론을 내릴 수 없음을 알 수 있다. <표 Ⅲ-2>에서 제시된 감정 지수는 한글 형태소 분석 사전6)을 바탕으로 긍정적 표현과 부정적 표현에 각각 1점과 –1점을 부여하고 이를 합산한 후 문서에 등장하는 단어의 총 개수로 나눈 값을 의미한다. <표 Ⅲ-2>에서 제시된 바와 같이 사업보고서의 현황 부분 원문은 평균적으로 다소 긍정적, 또는 표준편차를 감안하였을 때 전체적으로 중립적인 문체로 작성되었음을 확인할 수 있다. 그러나 요약문은 긍정적인 의미를 지닌 단어의 비중이 상대적으로 증가하였으며 요약문 사이의 편차 또한 증가하였다. 이와 같은 결과는 GPT를 이용한 기업 현황 분석에 대한 추가적인 검증이 필수적임을 시사하고 있다.
3. 정량적 분석: 재무 지표의 분석
이 절에서는 정량적인 평가 업무로서 공시된 재무 지표를 분석하여 유용성 있는 정보를 생산하는데 대형언어모형을 활용할 수 있는 방안을 살펴보고자 한다. 금융투자업은 방대한 양의 데이터를 처리하고 해석할 수 있는 능력이 요구되어 이를 효율적으로 정리하고 유용한 정보를 빠르게 추출하는 것은 매우 중요한 과정이라고 할 수 있다. 따라서 수시로 변화하는 시장 환경에 대응하여 신속하게 거래 전략을 수립하는 절차를 대형언어모형을 통하여 보조할 수 있을 경우 업무의 효율성을 제고할 여지가 있을 것이다.
<그림 Ⅲ-2>는 GPT를 활용하여 공시된 재무제표를 분석하는 작업의 예시를 보여주고 있다. 여기서 수행하는 작업은 기초적인 단계로서 연결재무제표를 정량적으로 이해하고 중요 변동 사항을 요약하는 과제이다. 연결재무제표는 일반적으로 양이 방대하여 기업의 평가와 투자 결정을 위한 분석에 유용한 정보를 신속하게 찾아내는 과정 자체가 전문적인 지식과 더불어 많은 시간의 투입이 필요하다. 이 과정을 대형언어모형이 단축할 수 있는 하나의 사례를 위 예시가 보여주고 있다.
위 사례에서 우선 검증해야 하는 부분은 수치의 사실관계이다. 해당 사례에 한하여서는 GPT가 수량에 대한 이해 및 연산을 비교적 정확하게 수행하고 있다고 볼 수 있다. 그러나 이는 앞서 설명하였듯이 확률적인 모형에 근거하여 도출된 결과이며 연산의 결과가 아님을 상기할 필요가 있다.7)
사실관계 확인에서 나아가 GPT를 통하여 작성된 재무 정보의 분석문이 전체 재무 지표가 내포하고 있는 정보량 대비 유지 또는 손실하였는지 확인할 필요가 있다. 정보 유용성을 평가하기 위하여 공시일 주변 초과수익률(
종속변수(
<표 Ⅲ-3>은 앞서 설명한 회귀분석 모형의 추정 결과를 보여주고 있다. 초과수익률과 수익률 변동성 모두의 경우에 대하여 비기대이익과의 상관관계가 감성지수가 높은 경우(
Ⅳ. 대형언어모형 활용의 위험 및 제약 요인
1. 할루시네이션 효과와 대응 방안
앞 절의 분석에서 시사하는 바와 같이 대형언어모형을 활용하여 금융정보를 분석할 경우 사실에 근거하지 않은 내용 또는 편향되거나 과장된 분석 결과를 얻을 수 있는 위험을 경계해야 한다. 이는 흔히 ‘환각’ 또는 ‘착시’로 번역되는 할루시네이션(hallucination) 현상과 밀접한 연관이 있다. 확률적인 과정에 기반하여 학습된 데이터에 포함되지 않은 출력물을 ‘생성’하는 모형의 특성상 거짓 또는 편향된 결과물을 만들 수 있는 가능성이 항상 존재하는데, 이는 언어모형의 결과물이 논리적인 사고 체계의 결과물이라는 오해와 결합하였을 때 특히 위험할 수 있다.
Ji et al.(2022)에서는 할루시네이션을 발생시키는 원인으로 학습 데이터의 문제와 모형의 학습 및 추론 과정의 문제를 지적하고 있다. 여기에 실무적인 활용 과정에서 발생할 수 있는 요소를 더하여 세 단계로 문제의 원인과 대응 방향을 제시하고자 한다(<그림 Ⅳ-1> 참조). 첫 번째로 학습에 사용된 데이터가 부정확하거나 편향된 정보를 포함하고 있는 경우 이를 바탕으로 개발된 모형 또한 부정확한 결과물을 생성할 수 있다. 두 번째 문제는 특정한 데이터에 지나치게 최적화된 과대적합(over-fitting) 모형의 경우 생성된 결과물이 새로운 정보를 반영하지 못하고 기존의 잘못된 정보를 답습하는 경우를 들 수 있다. 마지막으로 모형이 충분히 많은 사전 정보 또는 문맥을 동시에 고려하지 않을 경우 생성되는 답변이 문맥적인 연관성이 낮아져 무의미한 단어의 나열에 그칠 수 있다.
이와 같은 오류를 최소화하기 위해서는 다음과 같은 대응책을 고려할 수 있다. 우선, 개발 단계에서 학습에 사용될 데이터의 양적인 면과 동시에 질적인 면도 고려하여 광범위하고 지속적으로 수집할 수 있는 기반이 마련되어야 한다. 이어서 학습 및 검증 단계에서 과대적합 문제를 방지하기 위하여 적절한 목적함수를 설정하고 교차검증(cross-validation)을 강화하는 절차를 구축할 필요가 있다. 마지막으로 배포 및 사용 단계에서 금융전문가의 지식을 활용하여 결과물에 대한 피드백을 얻고 필요시 이를 바탕으로 모형을 개선할 수 있는 유연한 접근이 요구된다.11)
2. 대형언어모형 활용의 제약 요인
앞서 설명한 바와 같이 대형언어모형의 크기는 기하급수적으로 증가하는 추세이며 이는 동시에 모형을 학습시키는 데 필요한 비용 또한 기하급수적으로 증가하고 있음을 의미한다. <그림 Ⅳ-2>는 현재 개발 중이거나 배포된 대형언어모형들의 알려진 학습 비용이 크게 증가하고 있는 추세임을 보여주고 있다. 여기서 학습비용은 공개된 자료를 통해 추정된 값으로서 학습에 필요한 데이터를 구하는 비용, 모수를 계산하는 과정에서 사용되는 대용량 컴퓨팅(클라우드 등) 비용 등을 포함한다.
높은 개발 및 유지 비용은 금융투자업계로 하여금 대형언어모형에 대한 장기적인 투자를 주저하게 만드는 요인으로 작용할 수 있다. 특히, 비용은 상대적으로 쉽게 계산할 수 있으나 개발의 성공 여부와 기대효과에 대해서는 불확실성이 존재하는 상황에서 적극적인 변화를 추진하기 위한 공감대의 형성은 어려울 수 있다. CFA Institute는 금융투자업계가 이와 같은 불확실성 하에서 AI를 성공적으로 도입하기 위해서는 (1) AI 기술자와 금융전문가 사이의 소통과 더불어 (2) 장기적인 안목을 바탕으로 실험적인 투자를 지원하는 지도자의 역량이 필요함을 지적하였다(CFA Institute, 2021). 특히, 해당 보고서에서 제시된 성공 사례들이 모두 단기적인 성과보다 실패에서 배우는 과정을 중시했다는 점은 국내 금융투자업의 장기적인 발전 전략의 관점에서도 시사하는 바가 크다고 할 수 있다.
제도적인 제약으로서 금융투자업의 망분리 원칙은 주로 클라우드(cloud)등 원격, 고성능 컴퓨팅 설비에 기반하여 운영되는 대형언어모형의 실무적인 활용을 어렵게 하는 요인이 될 수 있다. 금융투자업은 고객의 계좌정보 등 심각한 보안 문제를 발생시킬 수 있는 정보를 다수 보유하고 있다는 점에서 현재의 클라우드에 기반한 대형언어모형의 활용이 어려운 제약이 있다. 따라서 정보 유출 위험에 노출되지 않으면서 고성능 AI 모형을 사용하는 방안으로 오픈소스(open source) 모형12)을 분리된 사내 네트워크상에서 개발 및 배포하는 방안을 고려해 볼 수 있다.
Ⅴ. 결론 및 시사점
국내 금융투자업 환경에서 대형언어모형의 성공적인 도입을 위하여 앞서 논의한 위험 및 제약 요인을 바탕으로 시사점을 크게 기술적인 면과 구조적인 면으로 나누어서 제시하고자 한다. 기술적인 차원에서는 높은 품질의 학습 데이터를 지속적으로 수집 및 활용할 수 있는 인프라의 구축이 선결과제라고 할 수 있다. 대형언어모형이 신뢰성 높은 결과물을 생성하기 위한 필수적인 전제조건은 대규모의 문헌 자료를 지속적으로 학습하고 그 과정에서 모수를 업데이트하는 개발 절차의 확립일 것이다. 따라서 양질의 언어 데이터를 꾸준히 그리고 적시에 공급할 수 있는 역량은 모형의 활용도와 직결되는 문제이다.
이와 같은 문제의식에 기반하여 금융투자업에서 언어모형을 개발 및 활용하기 위하여 사용할 수 있는 데이터의 종류를 생각해 볼 때, 유의미한 개선점을 도출할 수 있을 것이다. 일례로 본 고의 분석에서 사용된 사업보고서 데이터의 경우 금융감독원의 전자공시 시스템(DART)에서 제공하는 Open API를 활용하여 수집 및 처리할 수 있다. 하지만 문서 내에서 종종 발견되는 특수문자 및 영문, 한문 등 외래어의 일관되지 않은 용법은 특정 기업의 시계열적 분석뿐만 아니라 기업 사이의 비교를 위하여 대량의 보고서를 일괄적으로 처리하는 작업을 어렵게 하는 요소로서 작용할 수 있다. 이와 관련하여 XBRL 등 표준화된 공시 양식의 도입 등의 논의가 이루어지고 있는 점은 향후 기업 정보의 일괄적인 처리를 위한 인프라 구축 가능성과 이를 기반으로 한 신뢰성 있는 대형언어모형의 개발에 긍정적인 요소일 것이다.
구조적인 면에서 초거대 AI 모형을 개발 및 유지에 대한 관심이 제고되어야 할 것이다. 국내 금융투자업의 IT 역량의 척도로서 인적, 물적 자원의 집약도는 같은 분야의 글로벌 선도 기업과 비교하였을 때 크게 부족한 것으로 파악되고 있다(이효섭, 2023. 3. 14; 노성호, 2023). 이와 같은 상황에 비추어 보았을 때, 대형언어모형과 같은 첨단의 AI 기술을 활용하여 금융투자업의 장기적인 발전 동력을 마련하기 위해서는 최근 급격히 증가한 관심도가 개발 역량 및 기술 인프라에 대한 투자로 치환될 수 있도록 관심과 지원이 필요할 것이다.
1) 학습 데이터의 발전은 비단 양적인 면에서만 이루어진 것이 아니라 서로 다른 형태의 자료를 종합적으로 학습하는 멀티모달(multimodal) 모형으로 발전하고 있으며, 일례로 문서와 그림 정보를 동시에 학습한 Swin Transformer를 들 수 있다(Liu et al., 2021).
2) 대형언어모형을 활용할 때 사용자와의 짧은 문답을 통해 학습 데이터에 포함되지 않은 답변을 생성하도록 유도하는 과정을 프롬프트 엔지니어링(prompt engineering)이라고 한다. 이에 대해서는 Ⅲ-1.장에서 자세히 설명하고 있다.
3) 이처럼 중첩적인 학습 과정을 거치는 신경망 모형을 가리켜 Recurrent Neural Network(RNN) 이라고 한다. 이중 특히 불필요한 ‘기억’을 단계별로 점차 삭제해서 학습의 효율을 높인 형태가 Long-Short Term Memory(LSTM) 모형이다.
4) 이러한 특성은 거짓 정보를 마치 사실인 양 출력하는 이른바 할루시네이션(hallucination) 효과와 밀접하게 연관되어 있다. 할루시네이션의 정의와 대응 방안에 대해서는 다음 절에서 보다 자세히 설명하고자 한다.
5) OpenAI에서 공식적으로 제안하는 프롬프트 엔지니어링 방식은 다음 사이트에서 찾을 수 있다. https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
6) 이 연구에서는 KNU 한국어 감성사전(http://dilab.kunsan.ac.kr/knusl.html)을 분석 기준으로 사용하였다. 다만, 해당 사전은 금융 전문 용어에 대한 보완이 이루어지지 않은 일반적인 용법에 근거한 사전이며, 금융 전문 용어에 대한 추가적인 분석은 조수지ㆍ김흥규ㆍ양철원(2021) 등이 있다.
7) 실제로 간단한 방정식의 해를 구하는 문제에서도 추가적인 학습이 없을 경우 GPT-3는 첫 시도에서 약 31% 정도의 낮은 정답률을 나타낼 수 있다(Zong & Krishnamachari, 2023).
8) 개별종목
9) 개별종목
10) 비기대이익은 랜덤워크 가정에 근거하여 이번기의 주당순이익(EPS)과 지난기의 주당순이익의 차이로 계산하였다.
11) 이와 같은 절차를 흔히 Human-In-The-Loop(HITL)이라고 한다.
12) 이를테면 Meta에서 개발 및 배포하고 있는 LLaMA의 경우 오픈소스로 제공되어 외부망에 접속하지 않은 환경에서도 개발 및 사용이 가능하여 학습 과정에 대한 투명성이 제고될 뿐만 아니라 학습에 사용된 데이터가 조직 외부로 유출되는 상황을 방지할 수 있다.
참고문헌
노성호, 2023, 『금융산업에서의 인공지능(AI) 활용 방안에 따른 리스크 요인 분석』, 자본시장연구원 이슈보고서 23-13.
노성호, 2023, 생성형 AI에 의한 생산성 혁신과 금융업의 대응 방향, 자본시장연구원 『자본시장포커스』 2023-18호.
서범석ㆍ이영환ㆍ조형배, 2022, 『기계학습을 이용한 뉴스심리지수(NSI)의 작성과 활용』, 국민계정리뷰.
이효섭, 2023. 3. 14, 해외 IB의 발전전략 및 한국형 IB의 과제, 금융투자업의 글로벌 경쟁력 강화 방안 세미나 발표자료.
이효섭, 2023, 생성형 AI가 금융산업에 미치는 영향 – 혁신과 리스크요인, 『글로벌금융리뷰』 제4권 1호.
조수지ㆍ김흥규ㆍ양철원, 2021, 기업 재무분석을 위한 한국어 감성사전 구축, 『한국증권학회지』 제50권 2호.
Baily, M.N., Brynjolfsson, E., Korinek, A., 2023. 5. 10, Machines of mind: The case for an AI-powered productivity boom, Brookings Commentary.
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J. Q., Demszky, D., Donahue, C., Doumbouya, M., Durmus, E., Ermon, S., Etchemendy, J., Ethayarajh, K., Fei-Fei, L., Finn, C., Gale, T., Gillespie, L., Goel, K., Goodman, N., Grossman, S., Guha, N., Hashimoto, T., Henderson, P., Hewitt, J., Ho, D.E., Hong, J., Hsu, K., Huang, J., Icard, T., Jain, S., Jurafsky, D., Kalluri, P., Karamcheti, S., Keeling, G., Khani, F., Khattab, O., Koh, P.W., Krass, M., Krishna, R., Kuditipudi, R., Kumar, A., Ladhak, F., Lee, M., Lee, T., Leskovec, J., Levent, I., Li, X.L., Li, X., Ma, T., Malik, A., Manning, C.D., Mirchandani, S., Mitchell, E., Munyikwa, Z., Nair, S., Narayan, A., Narayanan, D., Newman, B., Nie, A., Niebles, J.C., Nilforoshan, H., Nyarko, J., Ogut, G., Orr, L., Papadimitriou, I., Park, J.S., Piech, C., Portelance, E., Potts, C., Raghunathan, A., Reich, R., Ren, H., Rong, F., Roohani, Y., Ruiz, C., Ryan, J., Re, C., Sadigh, D., Sagawa, S., Santhanam, K., Shih, A., Srinivasan, K., Tamkin, A., Taori, R., Thomas, A.W., Tramer, F., Wang, R.E., Wang, W., Wu, B., Wu, J., Wu, Y., Xie, S.M., Yasunaga, M., You, J., Zaharia, M., Zhang, M., Zhang, T., Zhang, X., Zhang, Y., Zheng, L., Zhou, K., Liang, P., 2021, On the opportunities and risks of foundation models, arXⅣ preprint arXⅣ:2108.07258.
CFA Institute, 2021, T-Shaped Teams: Organizing to Adopt AI and Big Data at Investment Firms.
Eloundou, T., Manning, S., Mishkin, P., Rock, D., 2023, GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models, Working Paper.
Epoch, 2022, Parameter, Compute and Data Trends in Machine Learning https://epochai.org/data/pcd
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., IshⅡ, E., Bang, Y., Dai, W., Madotto, A., Fung, P., 2022, Survey of Hallucination in Natural Language Generation, ACM Computing Surveys. Association for Computing Machinery 55 (12), 1–38.
Kim, A., Muhn, M., Nikolaev, V., 2023, Bloated Disclosures: Can ChatGPT Help Investors Process Financial Information? arXⅣ preprint arXⅣ:2306.10224.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B., 2021, Swin Transformer: Hierarchical Vision Transformer using Swifted Windows, arXⅣ preprint arXⅣ:2103.14030.
Luong, M.T., Pham, H., Manning, C.D., 2015, Effective approaches to attention-based neural machine translation, arXⅣ preprint arXⅣ:1508.04025.
McKinsey Global Institute, 2023, The economic potential of generative AI: The next productivity frontier.
Sevilla, J., Heim, L., Ho, A., Besiroglu, T., Hobbhahn, M., Villalobos, P., 2022, Compute trends across three eras of machine learning, 2022 International Joint Conference on Neural Networks (IJCNN), IEEE 1-8.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2017, Attention is all you need, Advances in neural information processing systems, 30.
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., Mann, G., 2023, Bloomberggpt: A large language model for finance. arXⅣ preprint arXⅣ:2303.17564.
Yang, H., Liu, X.Y., Wang, C.D., 2023, FinGPT: Open-Source Financial Large Language Models. arXⅣ preprint arXⅣ:2306.06031.
Zong, M., Krishnamachari, B., 2023, Solving math word problems concerning systems of equations with gpt-3, Proceedings of the AAAI Conference on Artificial Intelligence 37(13), 15972-15979.
Statista https://www.statista.com/chart/29174/time-to-one-million-users/